
State Key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications

Abstract
Previous 3D hand pose estimation methods primarily rely on a single modality, either RGB or depth, and the comprehensive utilization of the dual modalities has not been extensively explored. RGB and depth data provide complementary information and thus can be fused to enhance the robustness of 3D hand pose estimation. However, there exist two problems for applying existing fusion methods in 3D hand pose estimation: redundancy of dense feature fusion and ambiguity of visual features. First, pixel-wise feature interactions introduce high computational costs and ineffective calculations of invalid pixels. Second, visual features suffer from ambiguity due to color and texture similarities, as well as depth holes and noise caused by frequent hand movements, which interferes with modeling cross-modal correlations. In this paper, we propose Keypoint-Fusion for RGB-D based 3D hand pose estimation, which leverages the unique advantages of dual modalities to mutually eliminate the feature ambiguity, and performs cross-modal feature fusion in a more efficient way. Specifically, we focus cross-modal fusion on sparse yet informative spatial regions (i.e. keypoints). Meanwhile, by explicitly extracting relatively more reliable information as disambiguation evidence, depth modality provides 3D geometric information for RGB feature pixels, and RGB modality complements the precise edge information lost due to the depth noise. Keypoint-Fusion achieves state-of-the-art performance on two challenging hand datasets, significantly decreasing the error compared with previous single-modal methods.
Overview
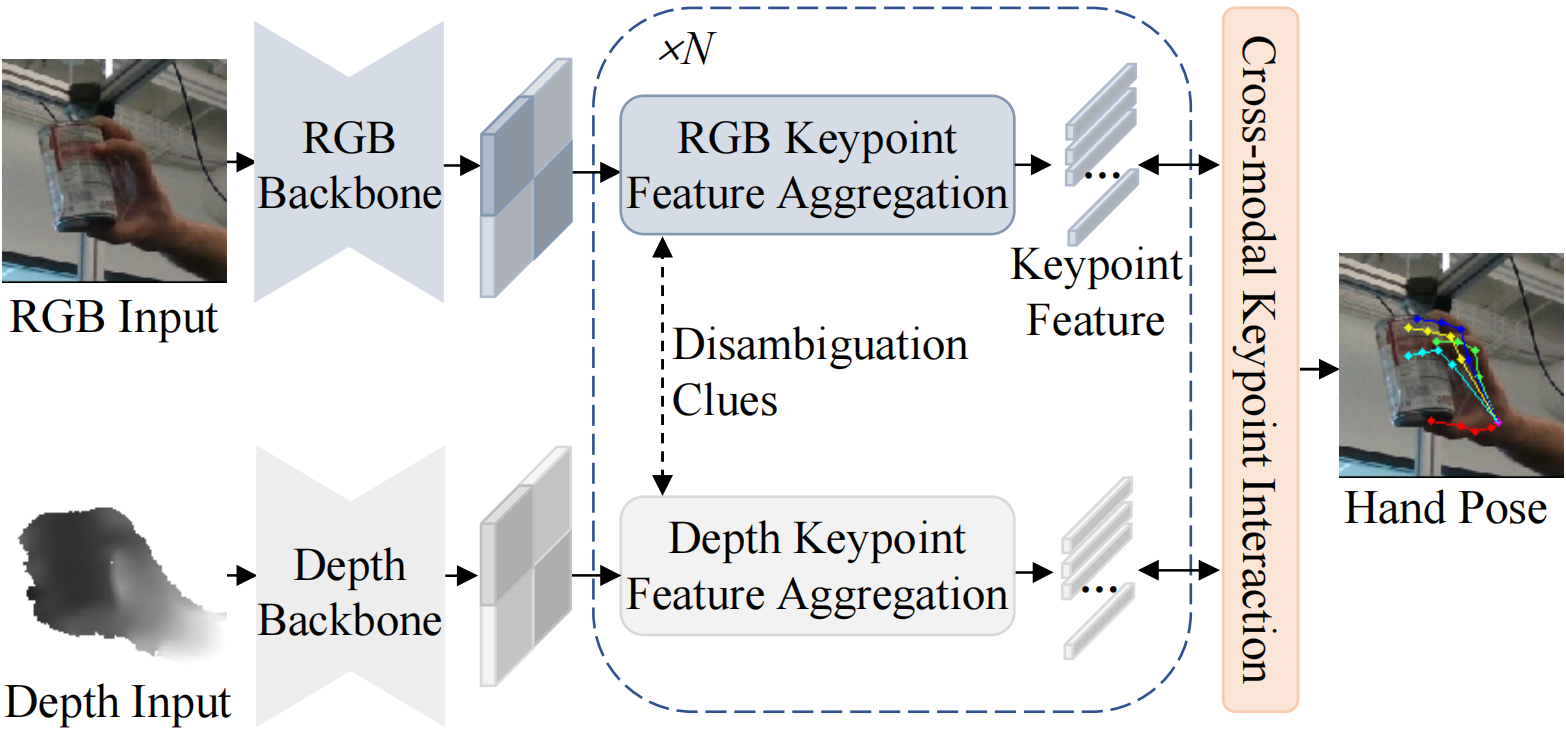
Keypoint-Fusion first extracts RGB-D visual features and predicts the initial hand pose. Then, the proposed KFAM aggregates RGB and depth local features around the joints, during which the unique advantages of complementary modalities are leveraged to clarify intra-modal ambiguous information. Finally, Keypoint-Fusion performs sparse cross-modal interaction between the aggregated keypoint feature.
Qualitative Results
.png)
Compared with the SOTA IPNet, our method demonstrates superior performance in:
✅ noise and depth holes (row 1, row 3, row 4).
✅ motion blur (row 2).
✅ severe occlusion (row 5, row 6, row 7).
.png)
Bibtex
@inproceedings{liu2024keypoint,
title={Keypoint Fusion for RGB-D Based 3D Hand Pose Estimation},
author={Liu, Xingyu and Ren, Pengfei and Gao, Yuanyuan and Wang, Jingyu and Sun, Haifeng and Qi, Qi and Zhuang, Zirui and Liao, Jianxin},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={38},
number={4},
pages={3756--3764},
year={2024}
}