
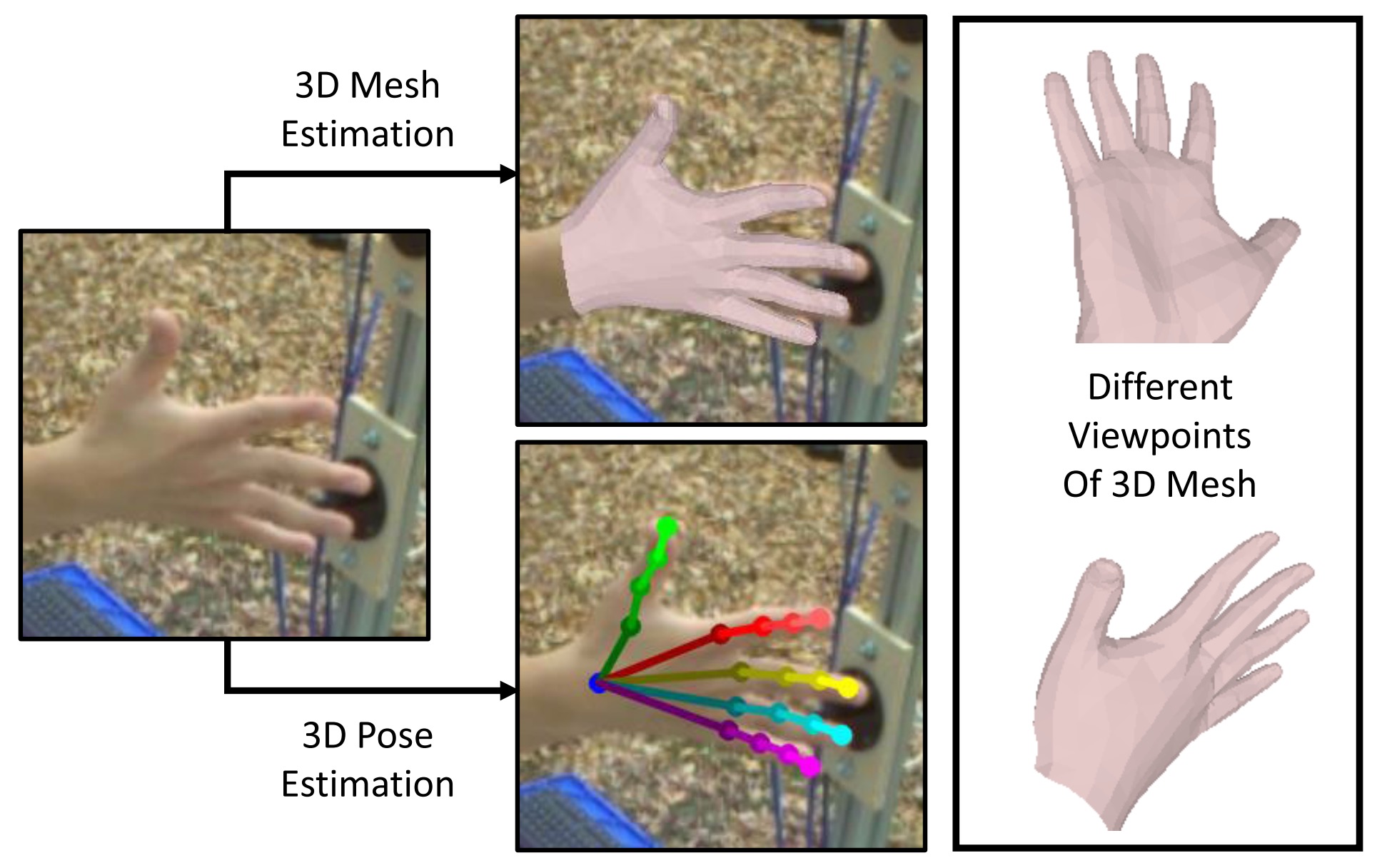
Abstract
3D hand reconstruction is an important technique for human-computer interaction. Interactive experience depends on the accuracy, efficiency, and robustness of the algorithm. Therefore, in this paper, we first propose a balanced framework called spatial-aware regression (SAR) to achieve precise and fast reconstruction. SAR can bridge convolutional networks and graph-structure networks more effectively than existing frameworks to fully exploit extracted spatial information using a novel spatial-aware initial graph building module. In addition, SAR uses adaptive-GCN to make keypoints interact efficiently and effectively; and regresses 2.5D belief maps to characterize uncertainty. SAR is highly flexible because it can predict an arbitrary number of keypoints and apply pose-guided refinement for coarse to fine regression. To produce more rational results for challenging cases and mitigate 3D label reliance, we also propose a more robust model-based framework called spatial-guided model-based regression (SMR) that is based on SAR. There are two critical designs of SMR: 1) it uses SAR to enhance the features with pose information to help the regression of hand model parameters; and 2) it regresses parameters in a spatially aware manner that is similar to SAR. Experiments demonstrate that the proposed frameworks surpass existing fully-supervised approaches on the FreiHAND, HO-3D, RHD, and STB datasets. Also, the performances of the proposed frameworks under weakly/self-supervised settings outperform other competitors. Meanwhile, the proposed frameworks are accurate and efficient.
Overview
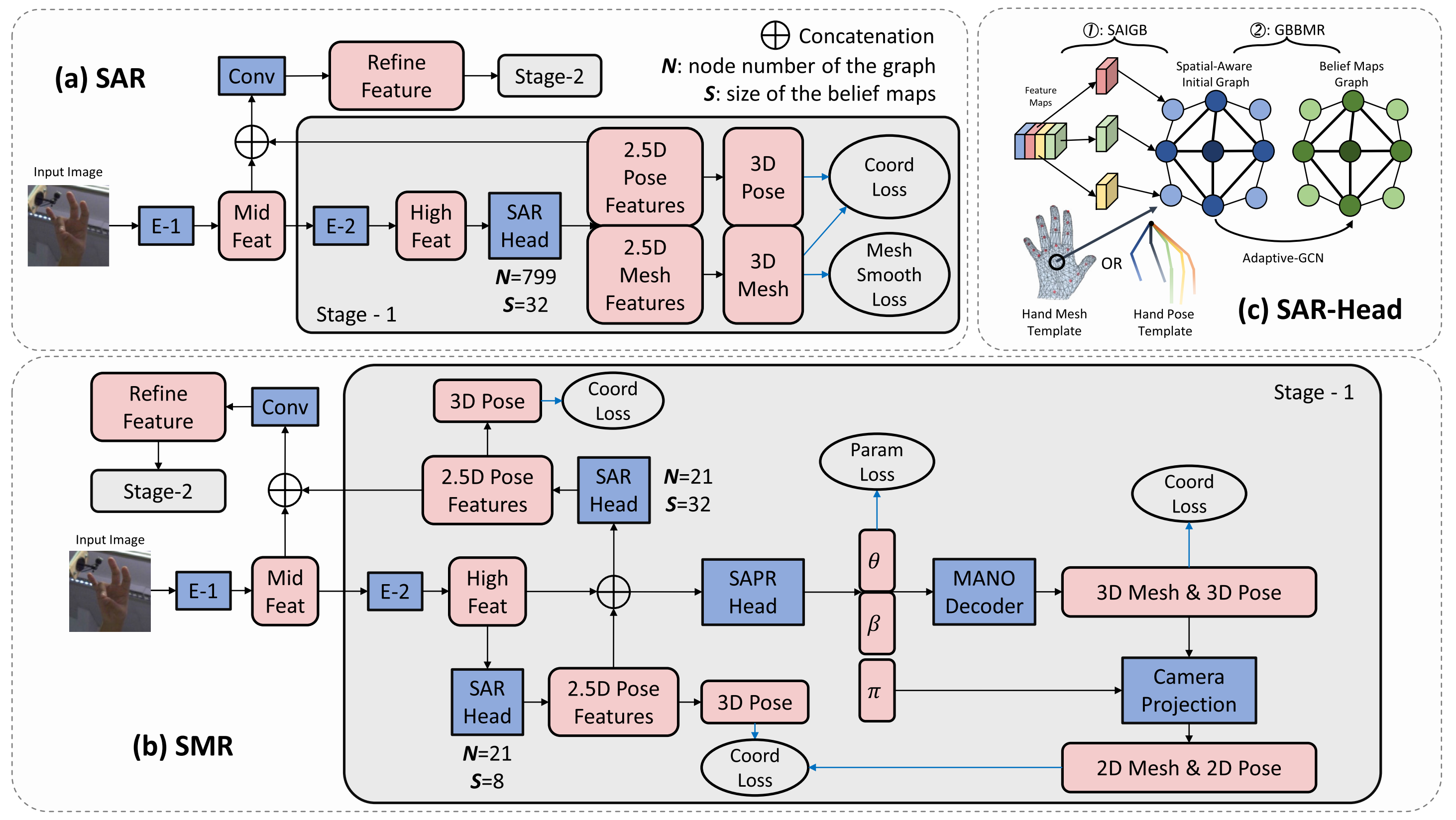
1️⃣ SAR first uses CNNs (E-1 and E-2) to extract feature maps from the input image. Then, SAR feeds the feature maps to SAR-Head (N=799, S=32) to regress the pose (21 keypoints) and mesh (778 keypoints) coordinates by decoding from the predicted 2.5D belief maps of resolution 32 × 32. Finally, SAR combines the 2.5D pose belief maps with the middle-level features from CNNs to the following stage for obtaining refined results.
2️⃣ SMR first uses CNNs to extract feature maps. Then, SMR uses a SAR-Head (N=21, S=8) to obtain the initial pose from the feature maps. Then, SMR combines the low-resolution 2.5D belief maps of the initial pose and the feature maps as the pose-guided features. Then, SMR feeds pose-guided features to SAPR-Head to regress the hand model (MANO) parameters (θ and β). SMR then uses the MANO layer to decode those parameters to a 3D hand mesh. The 3D hand pose is obtained by a linear regressor from the 3D hand mesh. The 2D hand mesh and pose are obtained by the weak-perspective camera projection from the 3D hand mesh and pose using the predicted camera parameters (π ). In addition, SMR also uses another SAR-Head (N=21, S=32) to obtain high-resolution 2.5D pose belief maps from the pose-guided features for multistage refinement.
3️⃣ SAR-Head uses the SAIGB module to build an initial feature graph with every keypoint containing several feature maps from CNNs. Then, it uses the GBBMR module to map the initial features to belief maps with Adaptive-GCN. N and S for SAR-Head denote targeting regressing keypoints number and the size of the predicted belief maps.
Qualitative Results
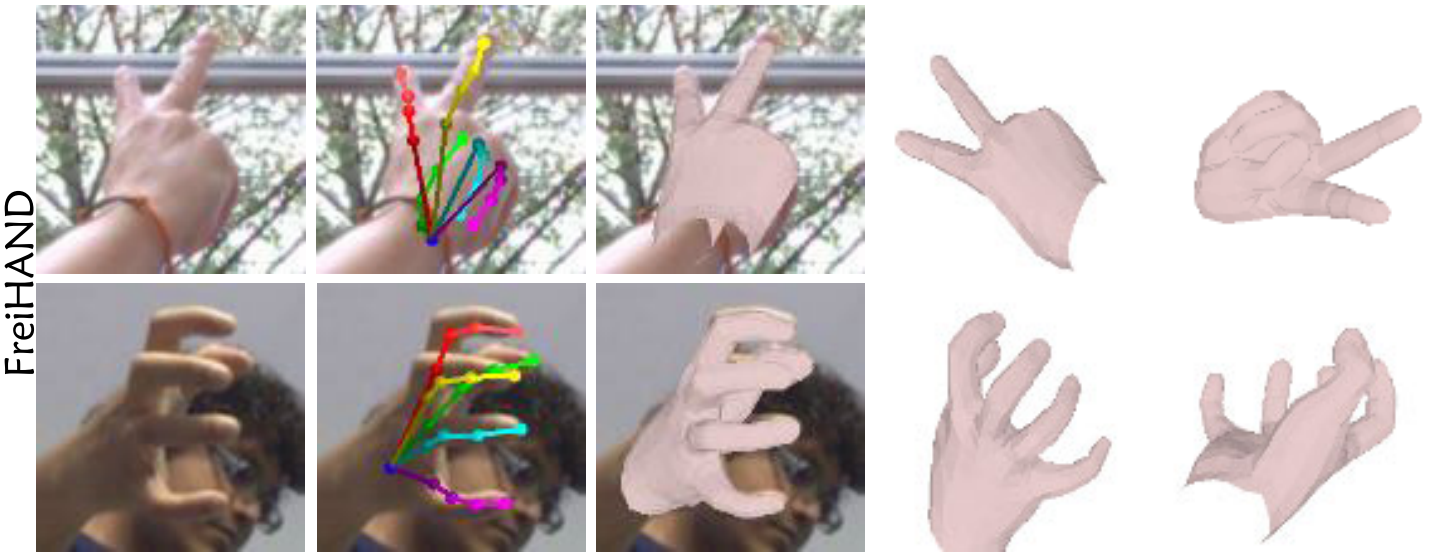
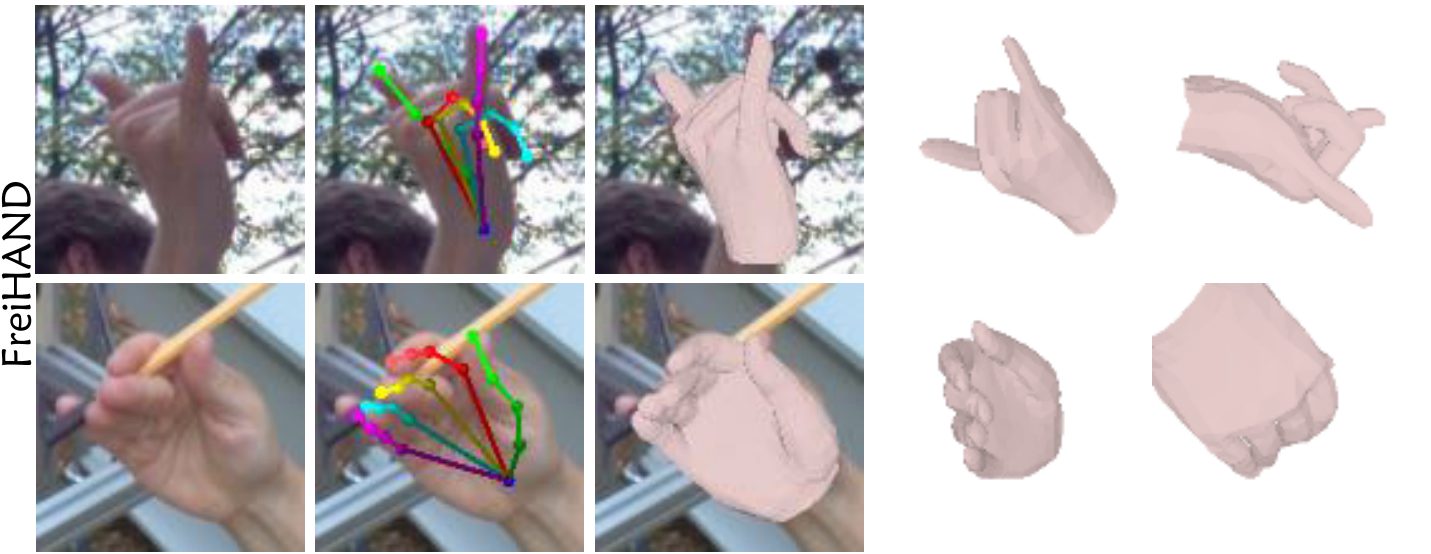
Visual results comparisons on FreiHAND:
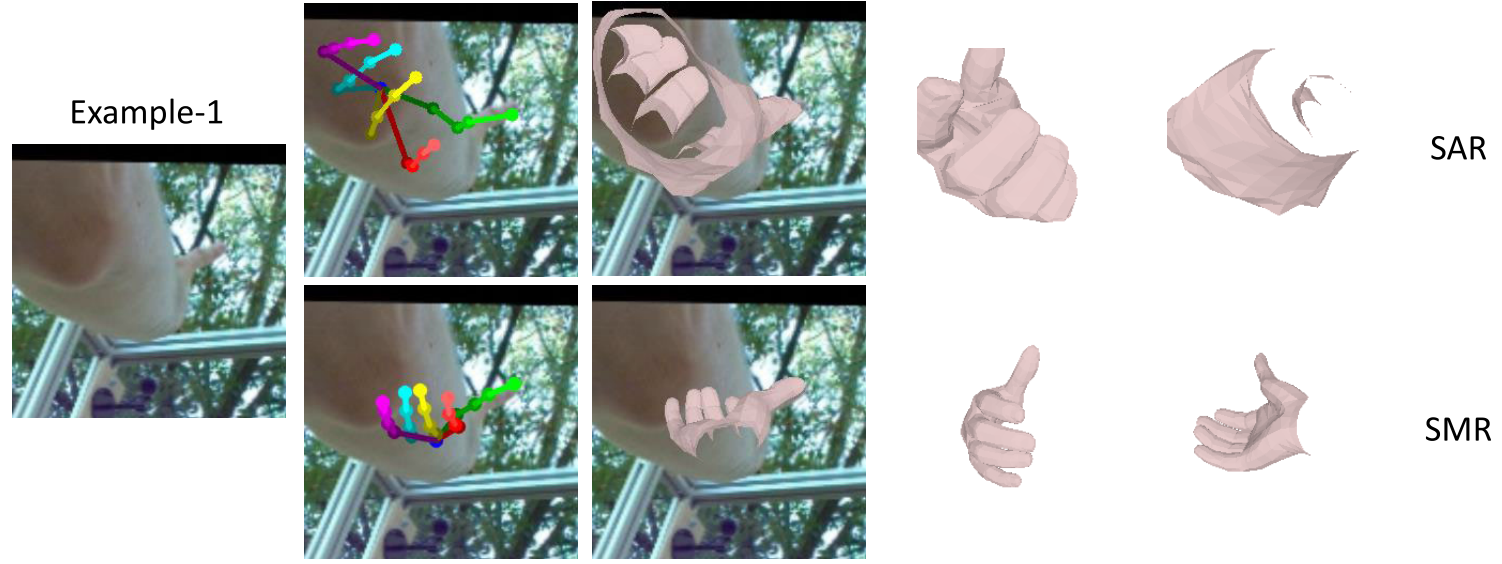


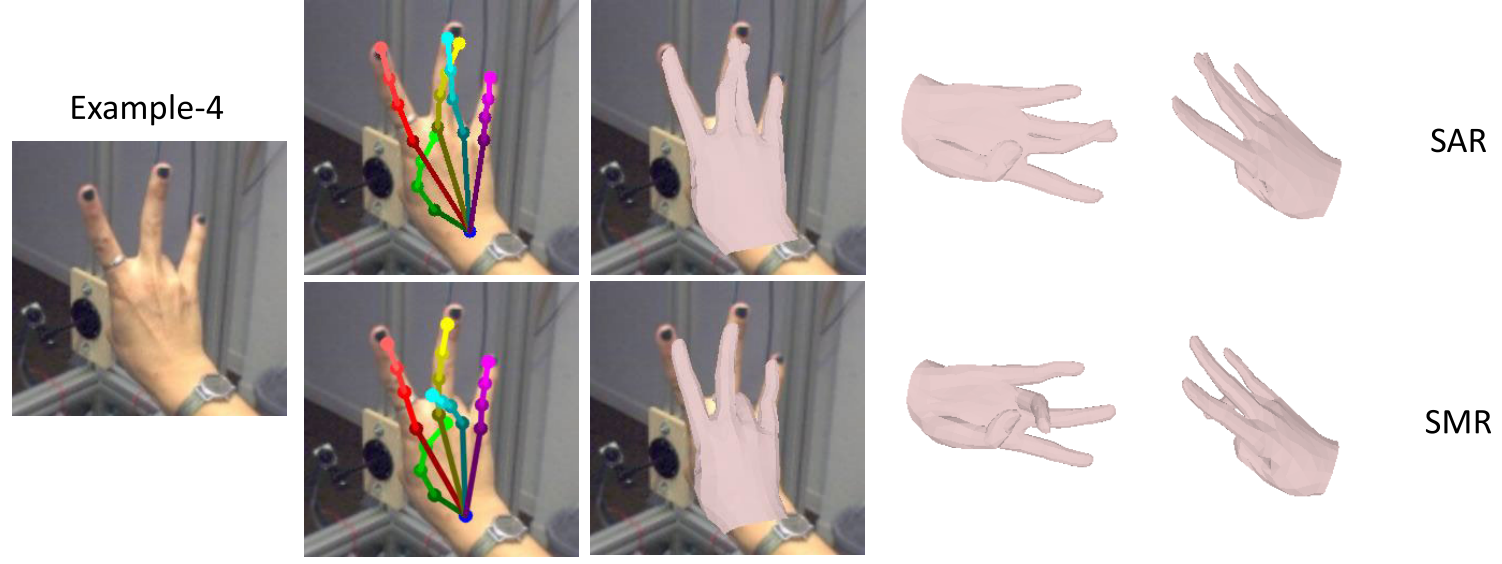
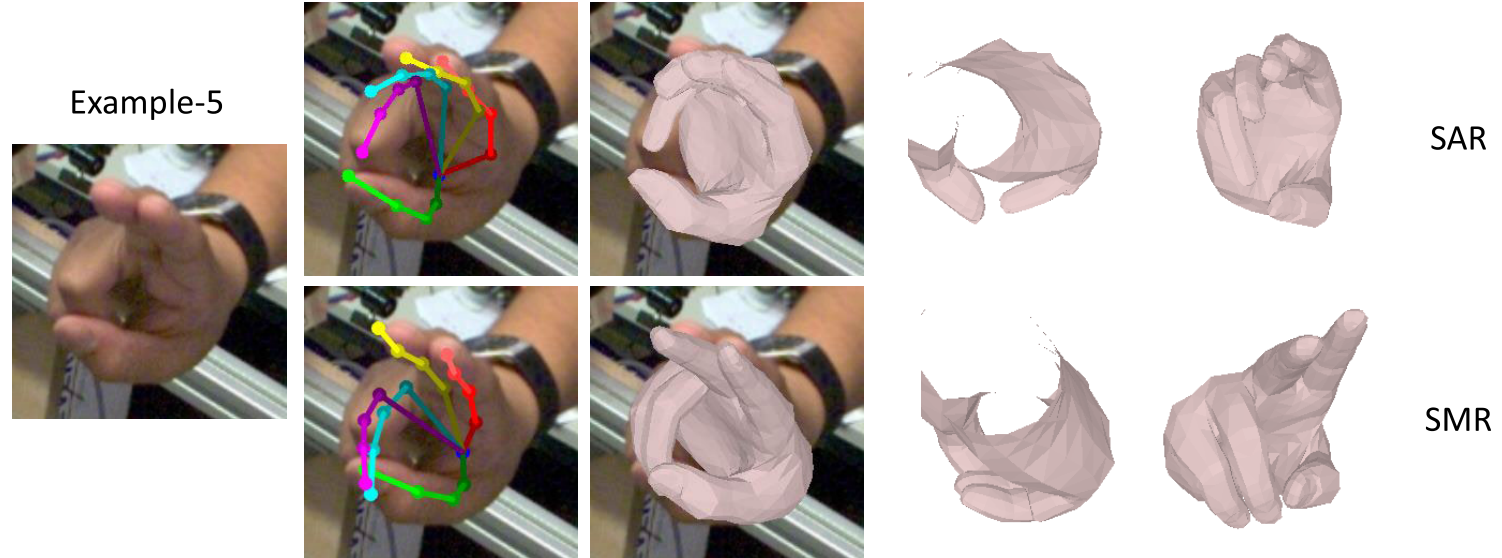
Cross-dataset visual results comparison:
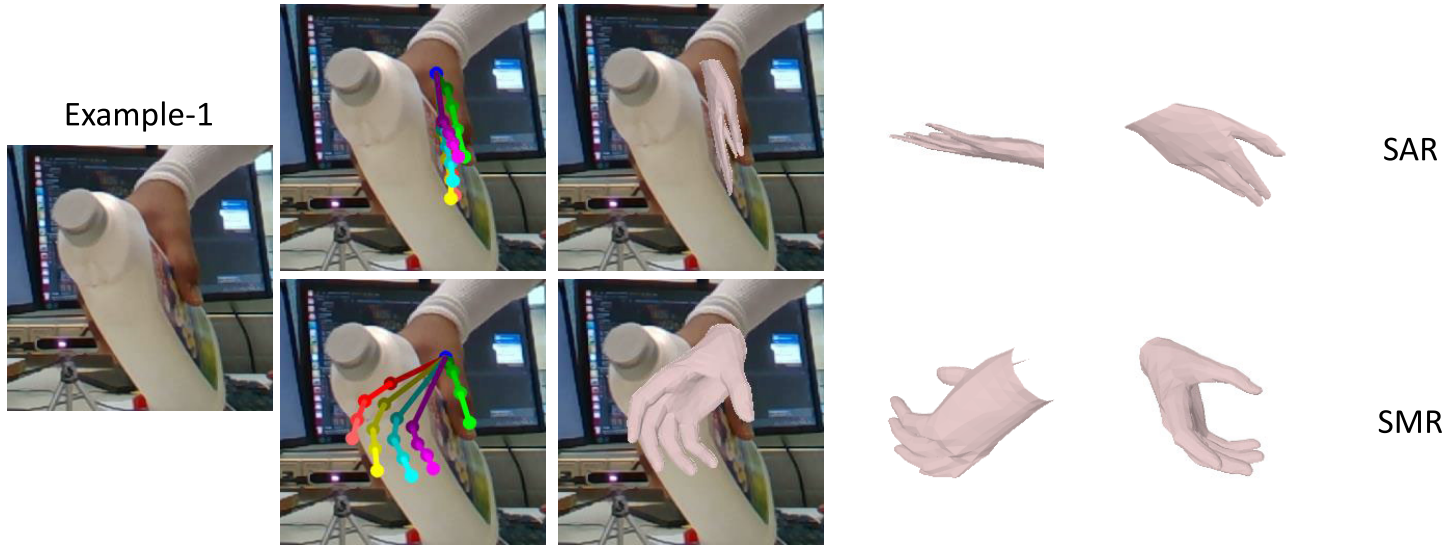
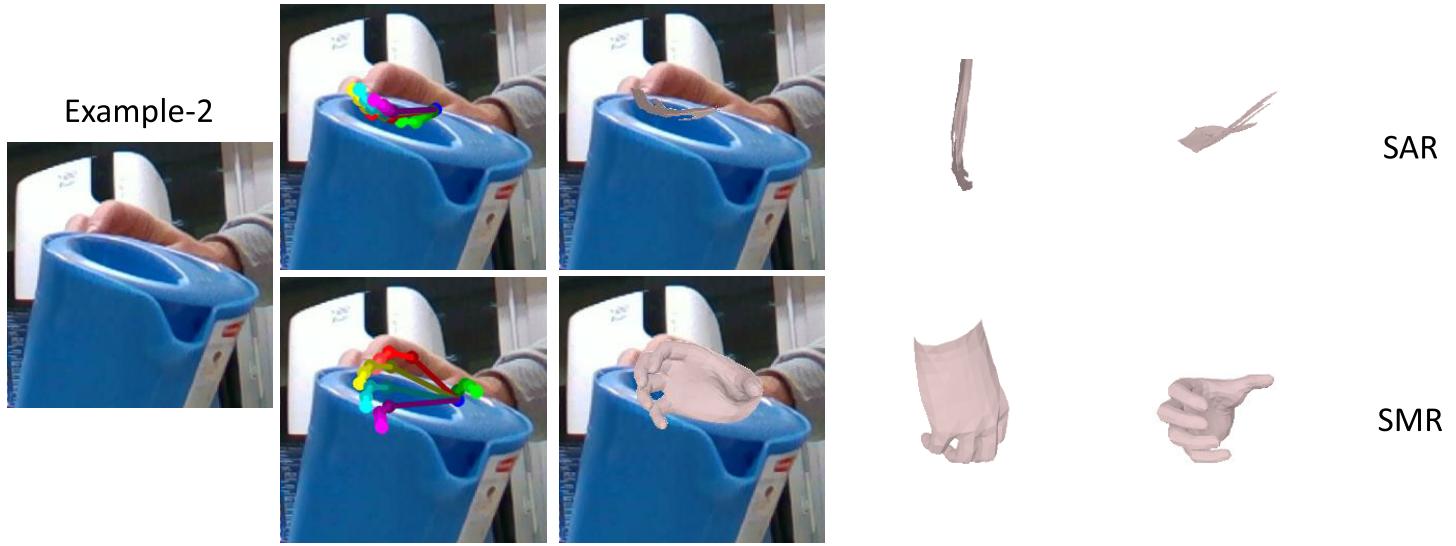
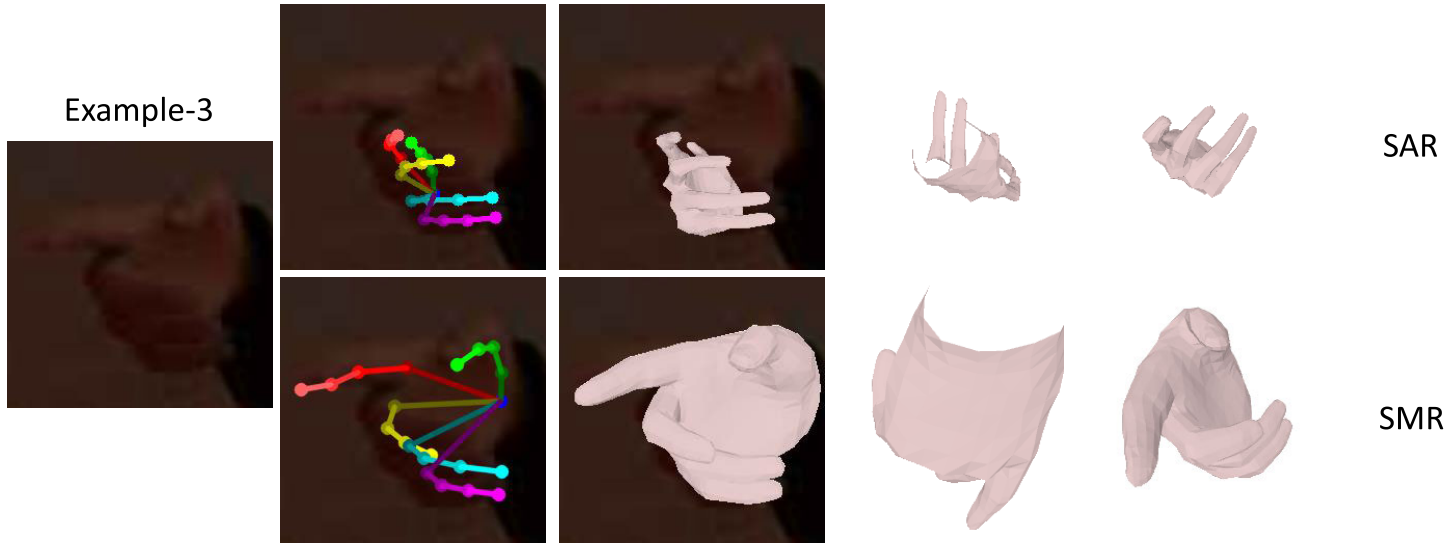
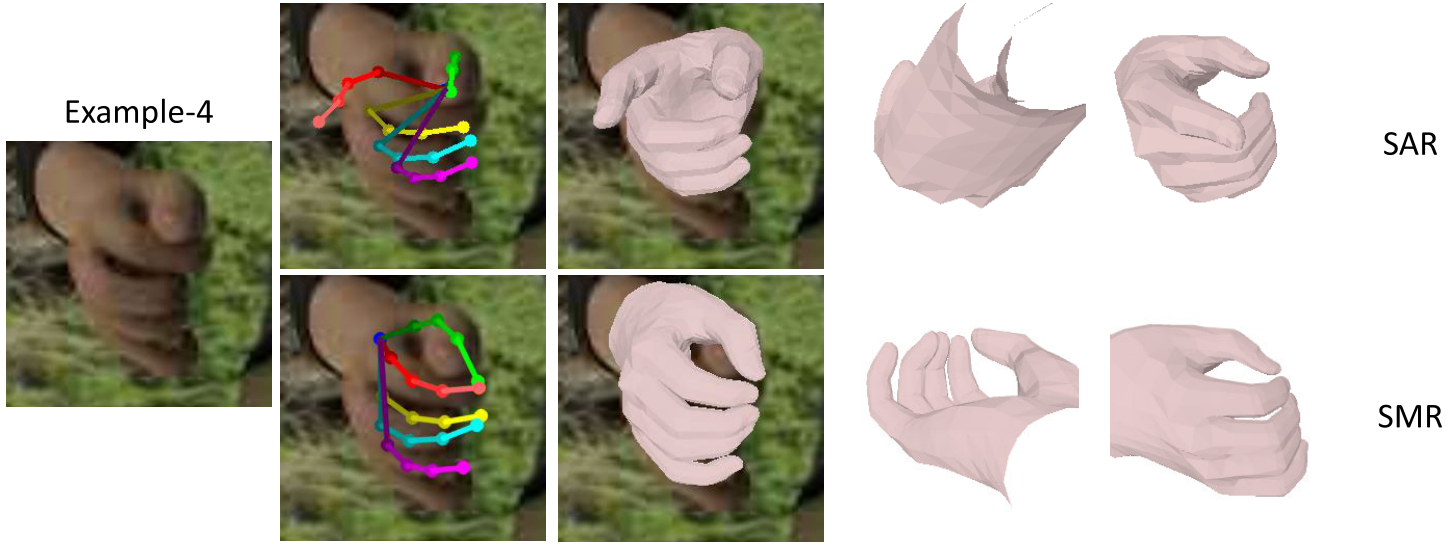

The visual results of SMR and the corresponding failure cases of SAR. Except under those typically difficult situations, SAR and SMR achieve similar performance to the result.
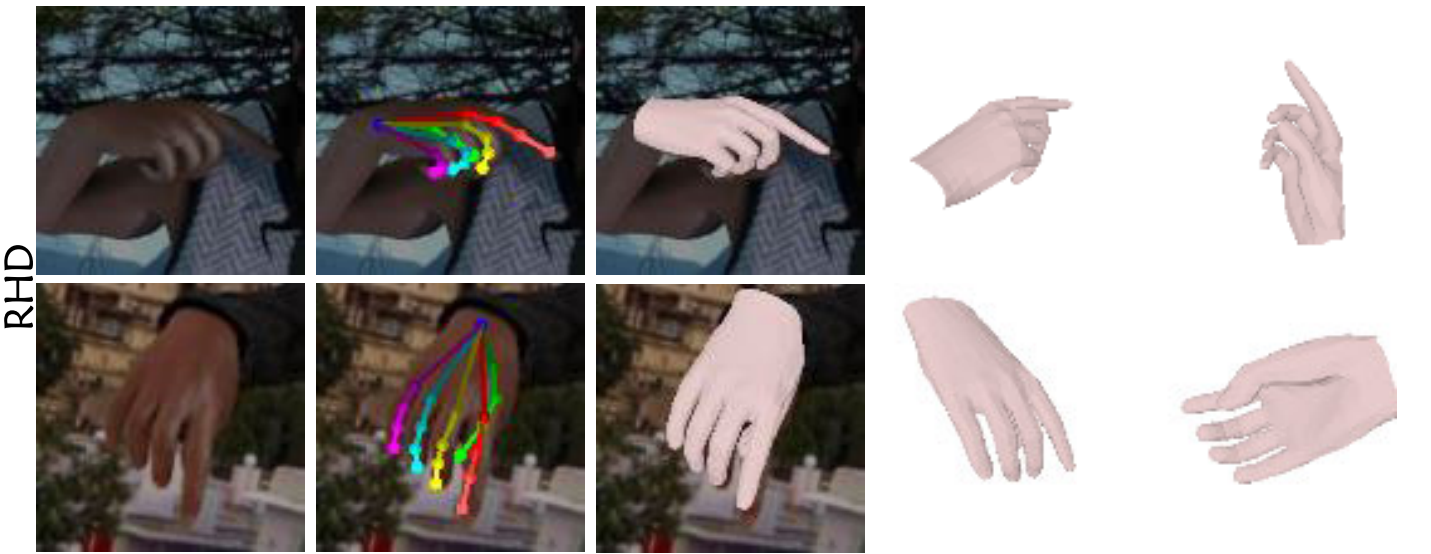
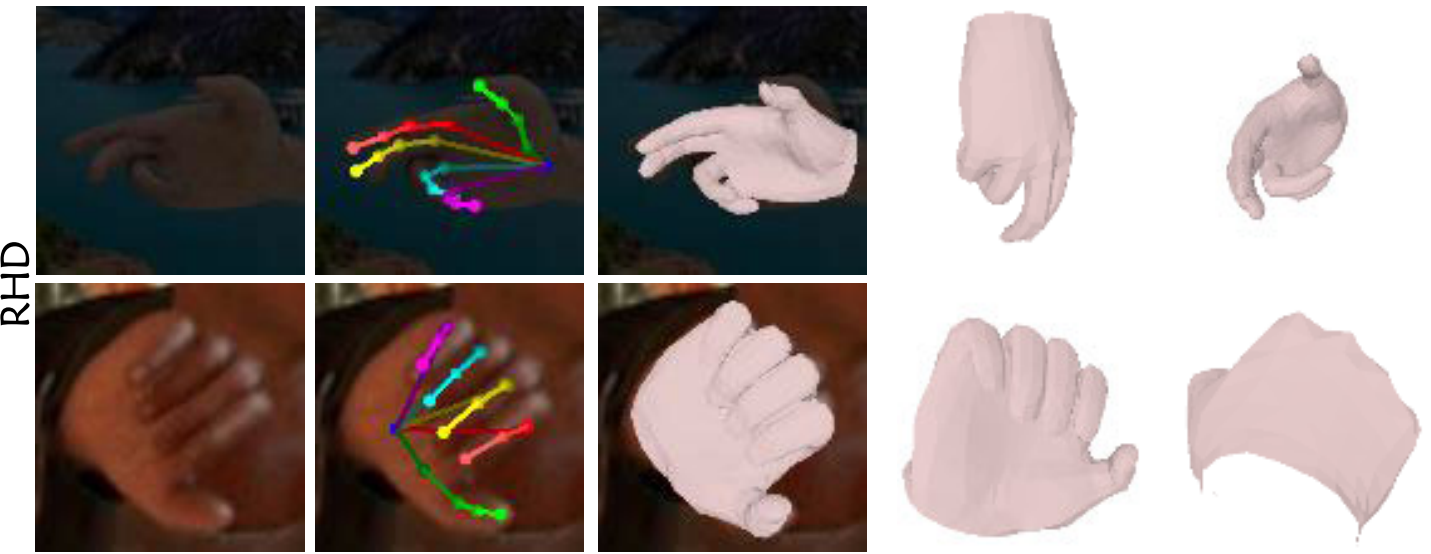
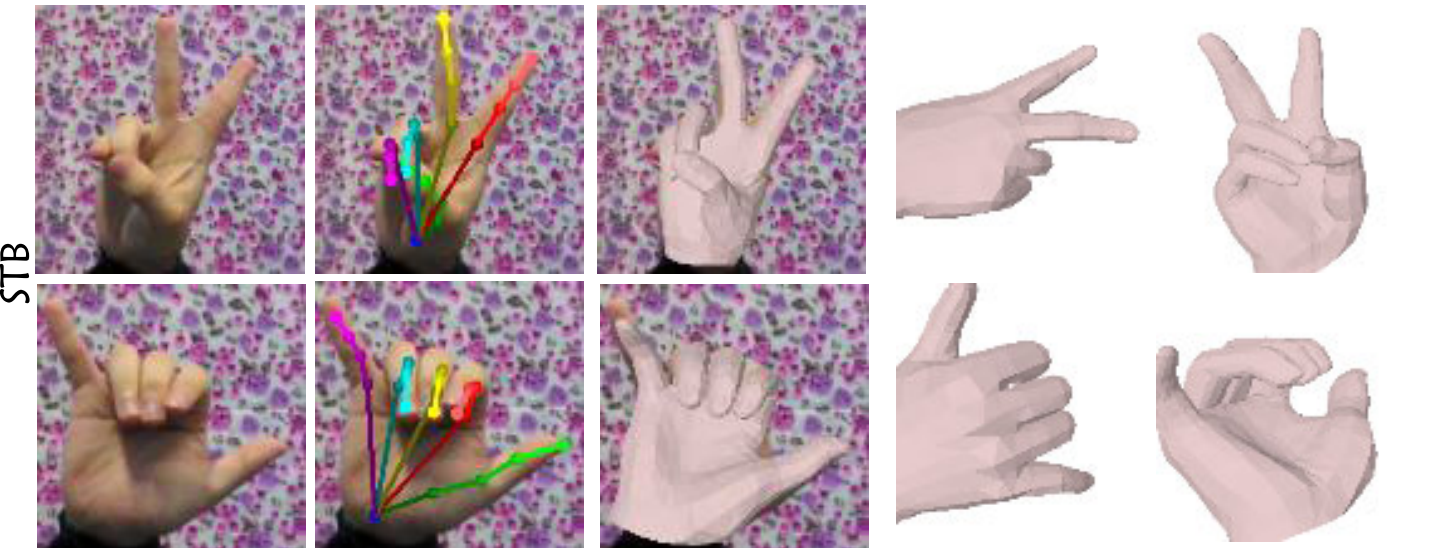
Visual results of SAR on the FreiHAND, HO-3D, RHD, and STB datasets:



Compare with SOTA
(Click “
” for details)
Fully-Supervised Learning
FreiHAND: SAR can achieve a good balance of accuracy and efficiency. SMR outperforms all other methods in terms of all the metrics mentioned above.
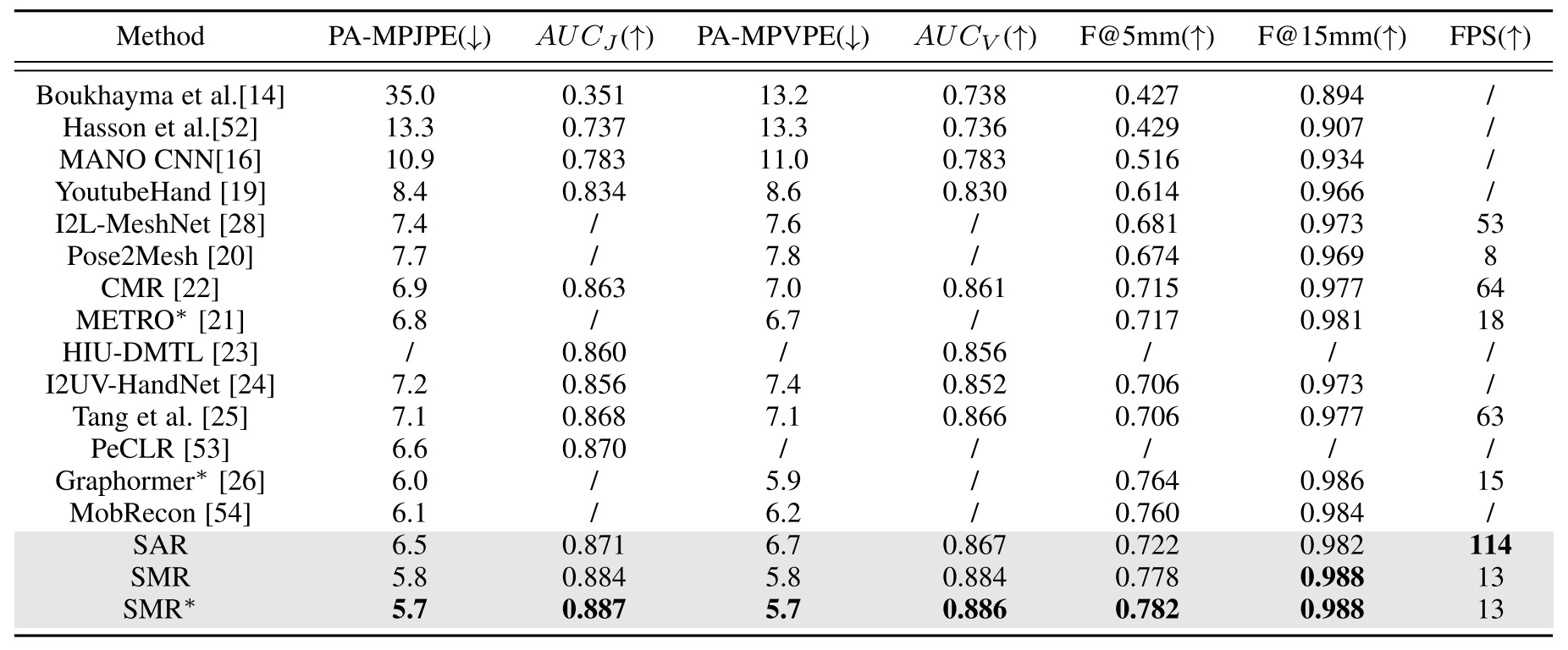
HO-3D: SMR outperforms SAR by a large margin. SAR can be overfitted more easily than SMR. SMR can obtain more robust results when hand-object occlusions occur due to the hand model information.
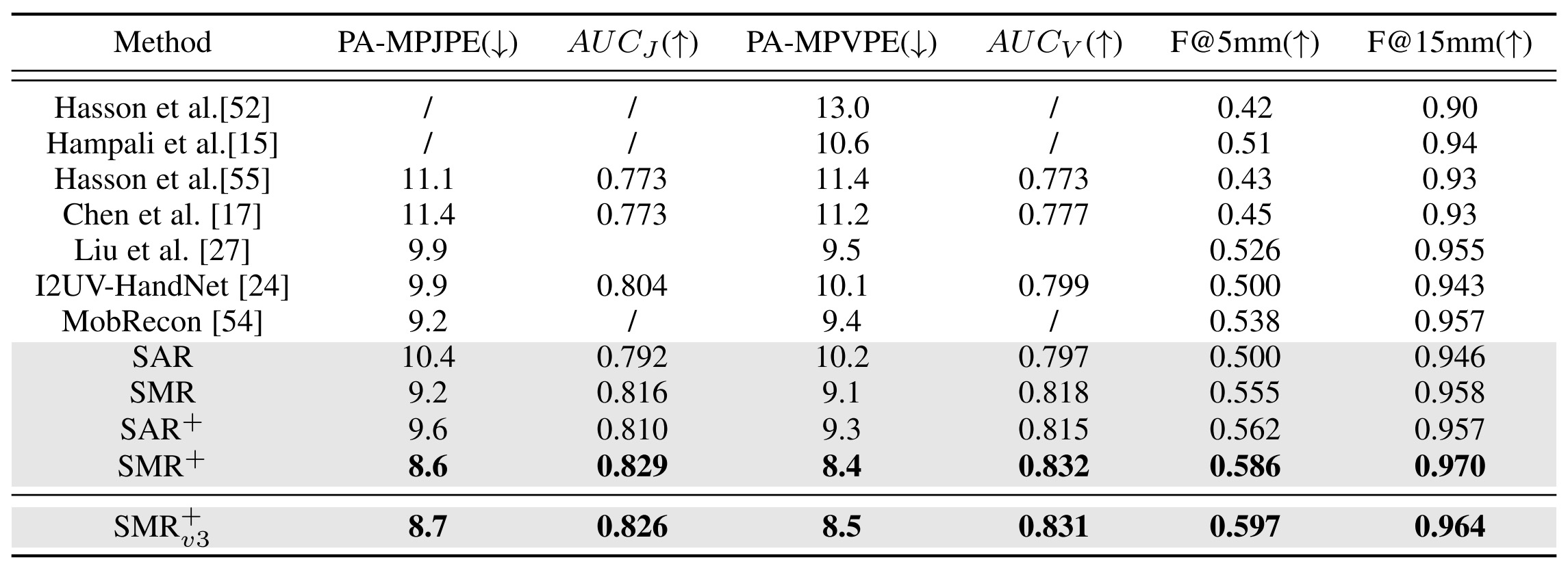
RHD & STB: SAR and SMR can achieve good performance on the RHD dataset and STB dataset.
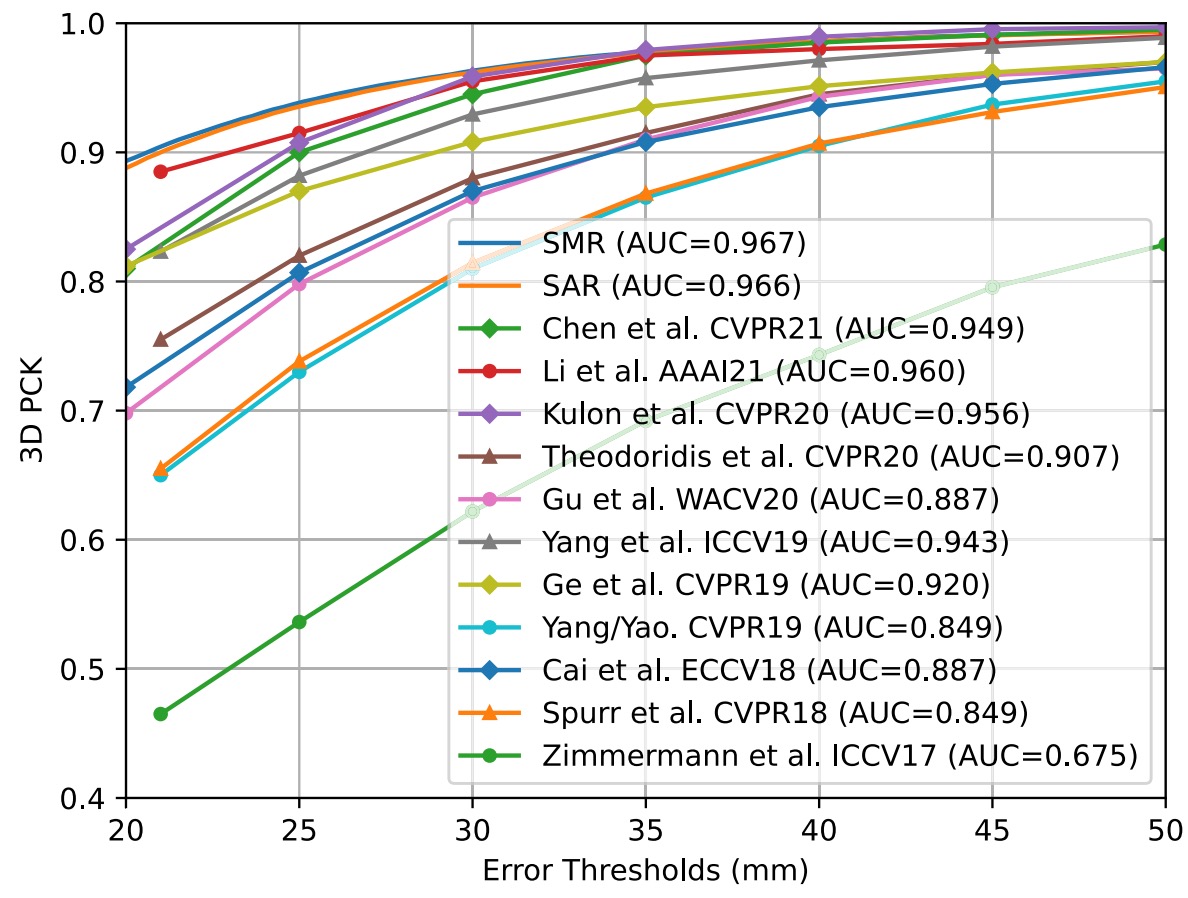
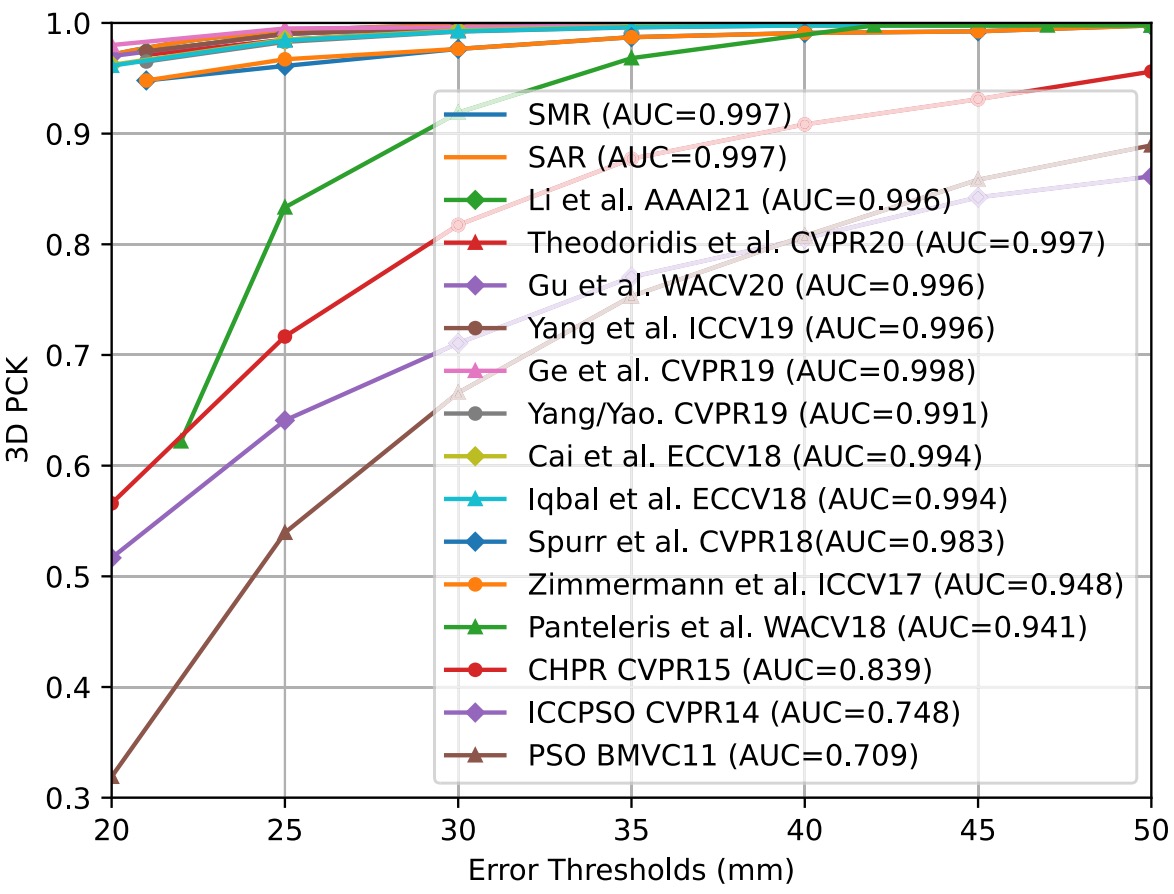
Weakly/Self-Supervised Learning
Because SMR uses the hand model as the decoder, it can be trained under label insufficient situations. Therefore, we also compare the proposed weakly/self-supervised performance with other methods on the FreiHAND dataset.
✅ When only using 2D labels for training, the performance surpasses recent competitors by a large margin.
✅ When conducting self-supervised training without using any manual annotations, the proposed method still outperforms S2HAND.
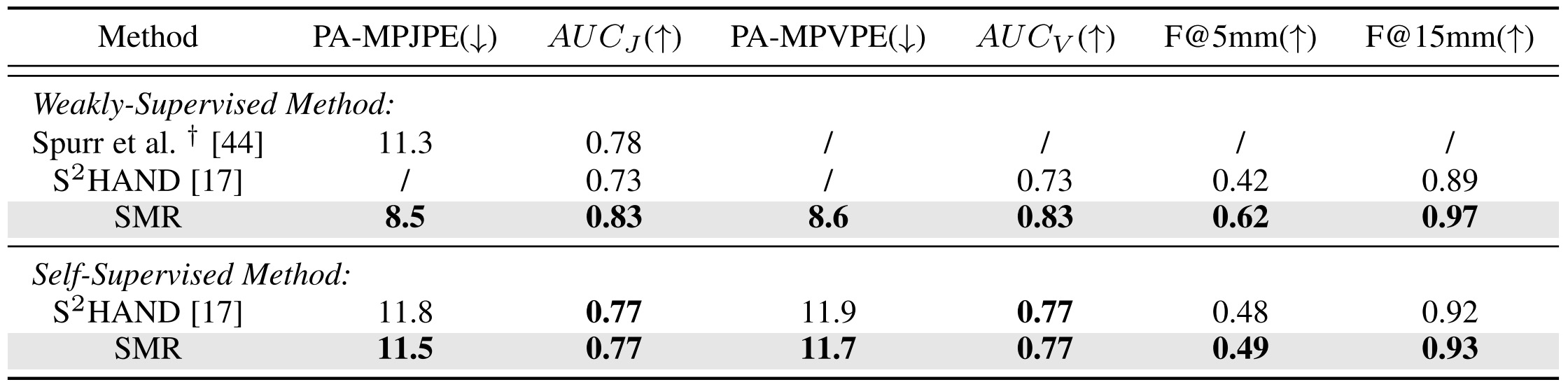
All these results demonstrate that a well-designed model-based framework can obtain more robust fully-supervised reconstruction and achieve remarkable performance under insufficient label situations.
Conclusion
We propose two frameworks for 3D hand reconstruction from a monocular RGB image, including SAR and SMR.
1️⃣ SAR achieves a good balance of accuracy and efficiency for keypoint localization tasks with the help of spatial-aware initial graph building, GCN-based belief maps regression, and pose-guided refinement.
2️⃣ In addition to SAR, SMR incorporates the hand model to provide hand prior information and enhances the model-based method with pose-guided features and spatial-aware parameter regression, which can address challenging cases and label insufficiency.
Extensive experiments on four public benchmarks show that the proposed methods can achieve good performance under fully/weakly/self-supervised settings with a high inference speed.
Bibtex
@article{sun2023smr,
title={SMR: Spatial-Guided Model-Based Regression for 3D Hand Pose and Mesh Reconstruction},
author={Sun, Haifeng and Zheng, Xiaozheng and Ren, Pengfei and Wang, Jingyu and Qi, Qi and Liao, Jianxin},
journal={IEEE Transactions on Circuits and Systems for Video Technology},
volume={34},
number={1},
pages={299--314},
year={2023},
publisher={IEEE}
}