
1Beijing University of Posts and Telecommunications, 2State Key Laboratory of Networking and Switching Technology, 3China Mobile Research Institute
Abstract
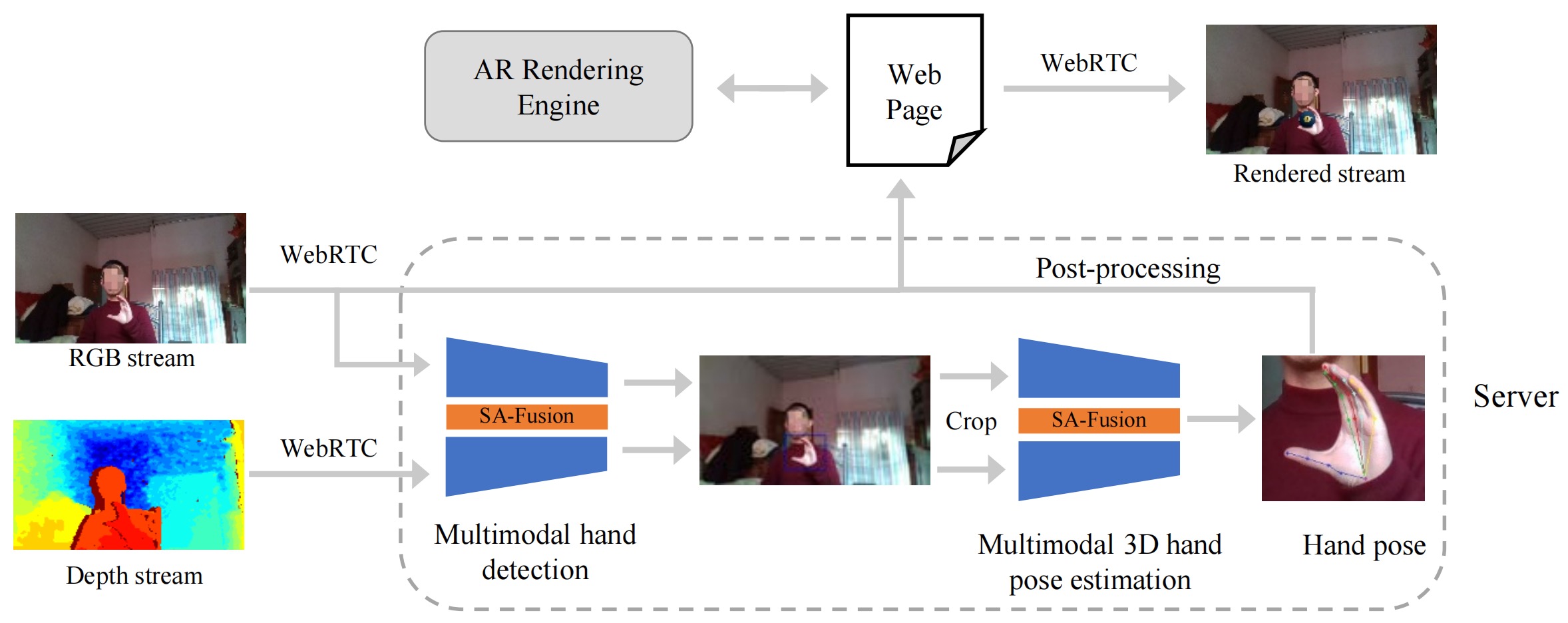
Web-based AR technology has broadened human-computer interaction scenes from traditional mechanical devices and flat screens to the real world, resulting in unconstrained environmental challenges such as complex backgrounds, extreme illumination, depth range differences, and hand-object interaction. The previous hand detection and 3D hand pose estimation methods are usually based on single modality such as RGB or depth data, which are not available in some scenarios in unconstrained environments due to the differences between the two modalities. To address this problem, we propose a multimodal fusion approach, named Scene-Adapt Fusion (SA-Fusion), which can fully utilize the complementarity of RGB and depth modalities in web-based HCI tasks. SA-Fusion can be applied in existing hand detection and 3D hand pose estimation frameworks to boost their performance, and can be further integrated into the prototyping AR system to construct a web-based interactive AR application for unconstrained environments. To evaluate the proposed multimodal fusion method, we conduct two user studies on CUG Hand and DexYCB dataset, to demonstrate its effectiveness in terms of accurately detecting hand and estimating 3D hand pose in unconstrained environments and hand-object interaction.
Overview
Qualitative results

(a) AWR
(b) Ours
(c) GT

(a) AWR
(b) Ours
(c) GT
Qualitative results of the single-modal AWR and our multimodal method integrated with SA-Fusion on DexYCB test dataset.
The above results illustrate that the proposed SA-Fusion can efectively improve the performance of existing 3D hand pose estimation methods in hand-object interaction scenarios.
Comparison with SOTA
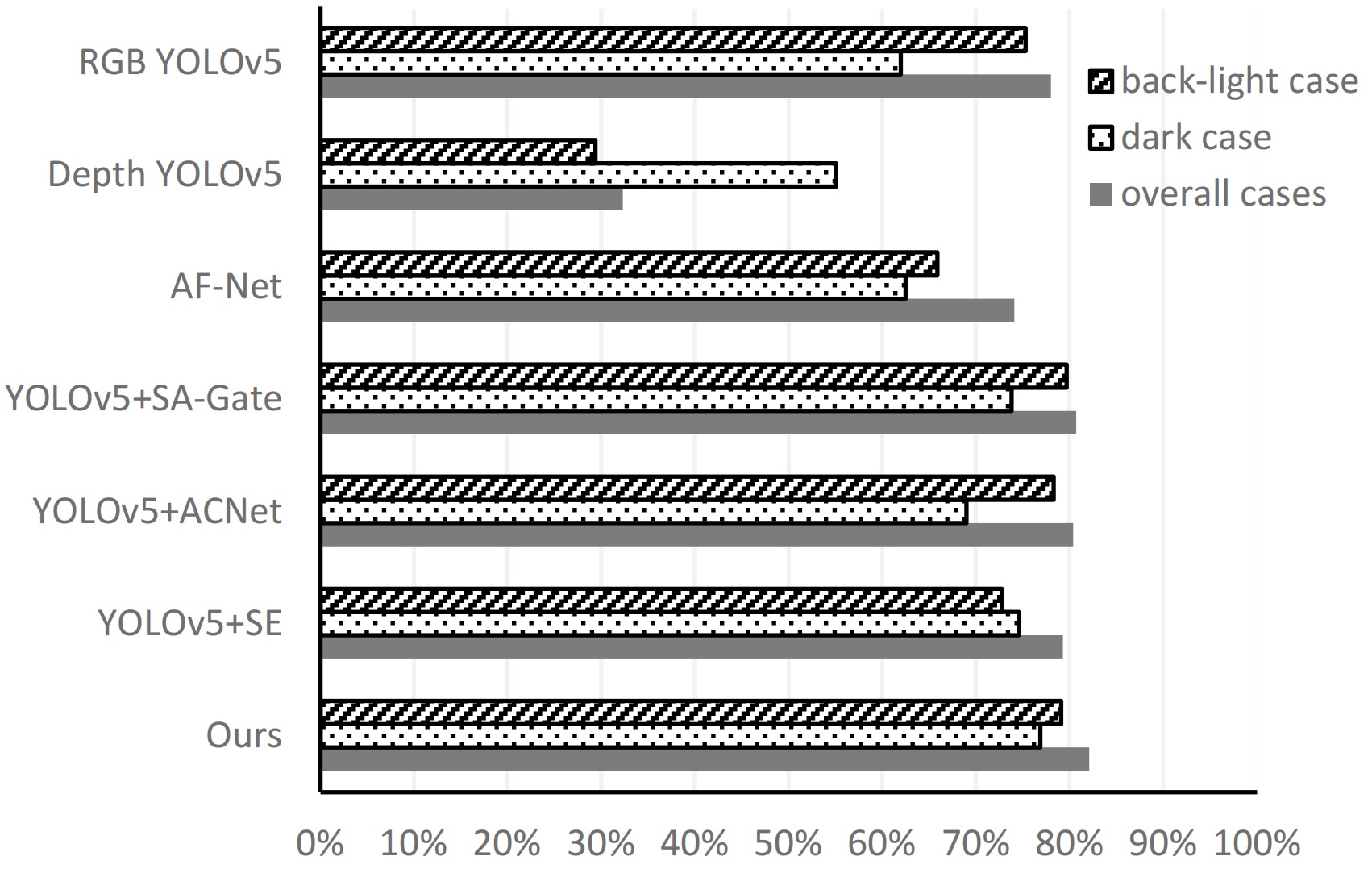
User Study 1: Hand Detection
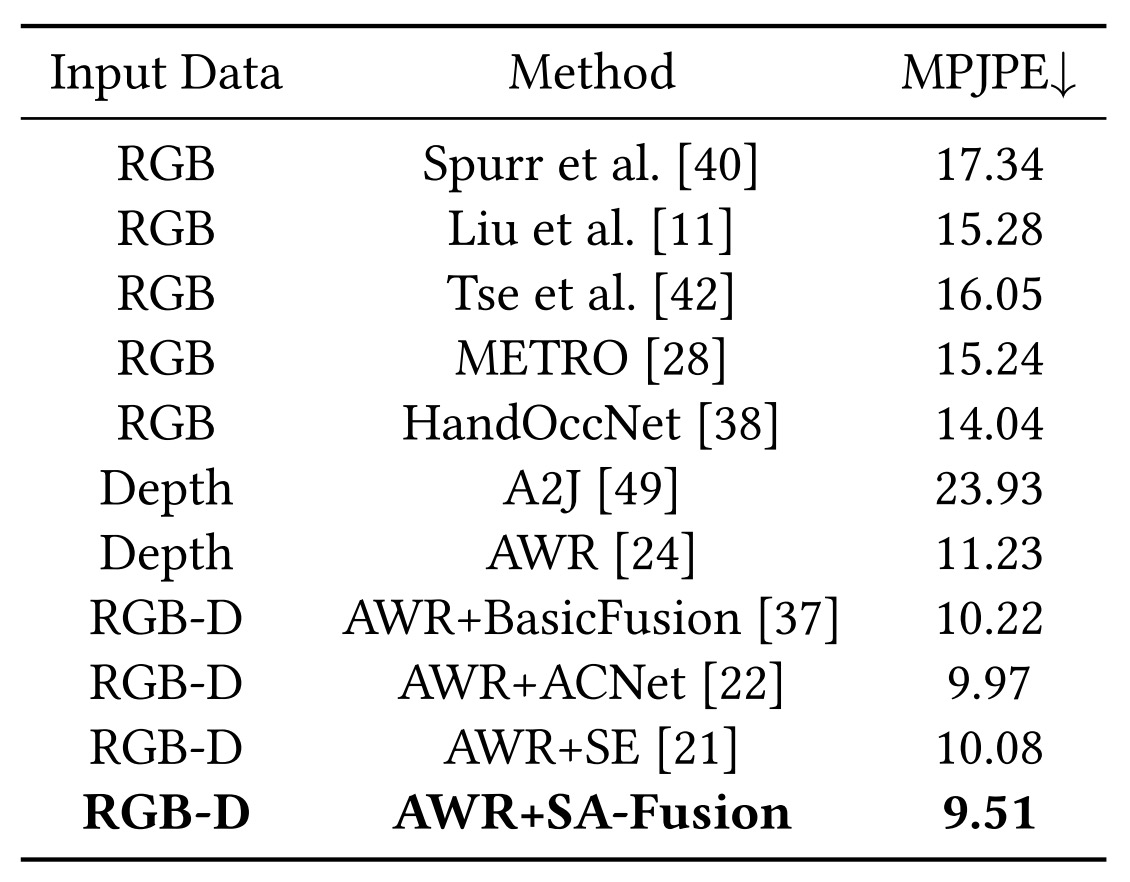
User Study 2: 3D Hand Pose Estimation
Conclusion
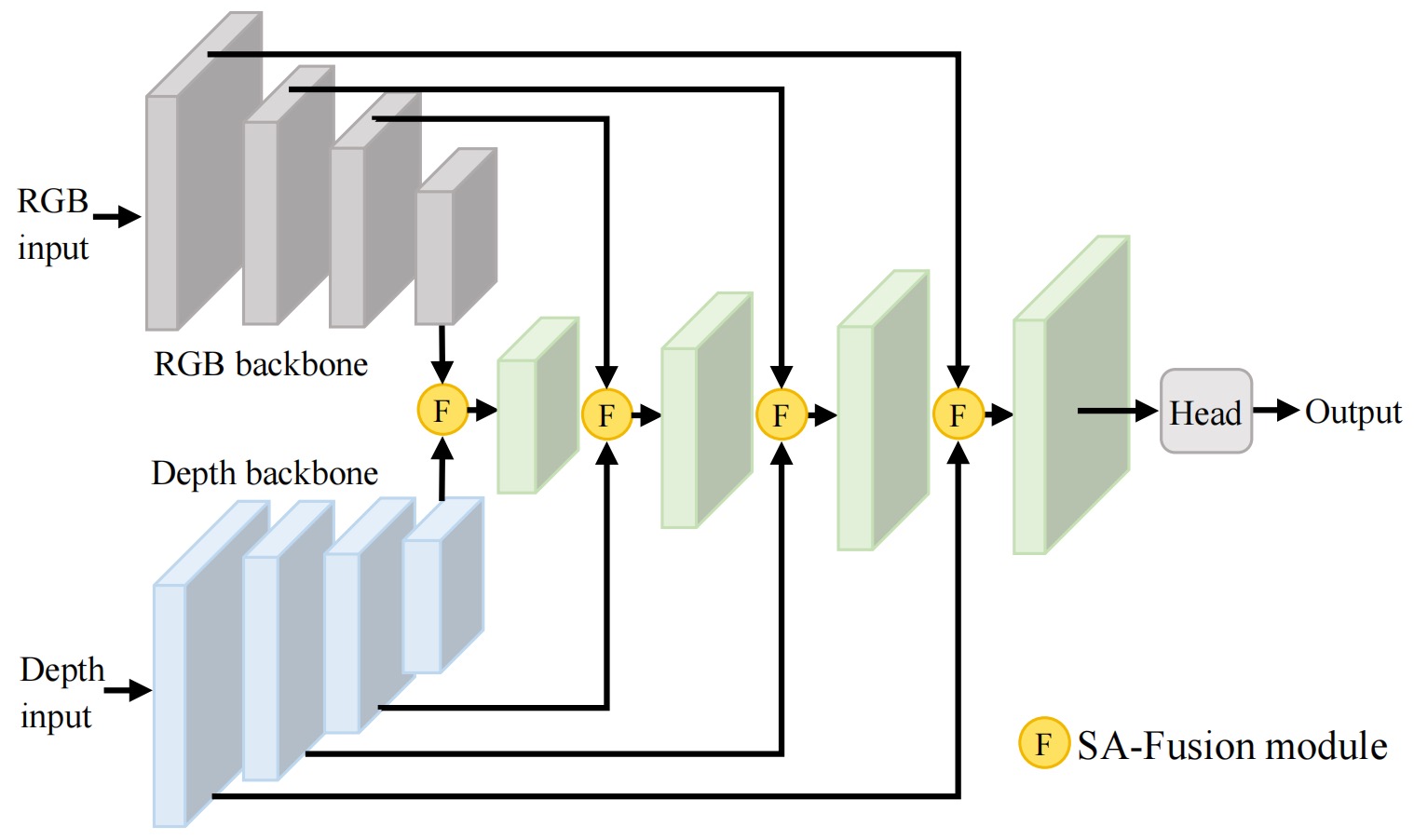
✅ We propose Scenes-Adapt Fusion, a multimodal fusion approach that can fully utilize the complementarity of RGB and depth modalities in unconstrained environments, to solve the problem of poor applicability of previous single-modal HCI methods in real-world scenarios. By applying the proposed SA-Fusion module to existing hand detection and 3D hand pose estimation frameworks, their performance has been significantly improved.
✅ Furthermore, we build a web-based interactive AR application by integrating the proposed multimodal HCI frameworks into the prototyping AR system.
Bibtex
@inproceedings{liu2023sa,
title={SA-Fusion: Multimodal Fusion Approach for Web-based Human-Computer Interaction in the Wild},
author={Liu, Xingyu and Ren, Pengfei and Chen, Yuchen and Liu, Cong and Wang, Jing and Sun, Haifeng and Qi, Qi and Wang, Jingyu},
booktitle={Proceedings of the ACM Web Conference 2023},
pages={3883--3891},
year={2023}
}