
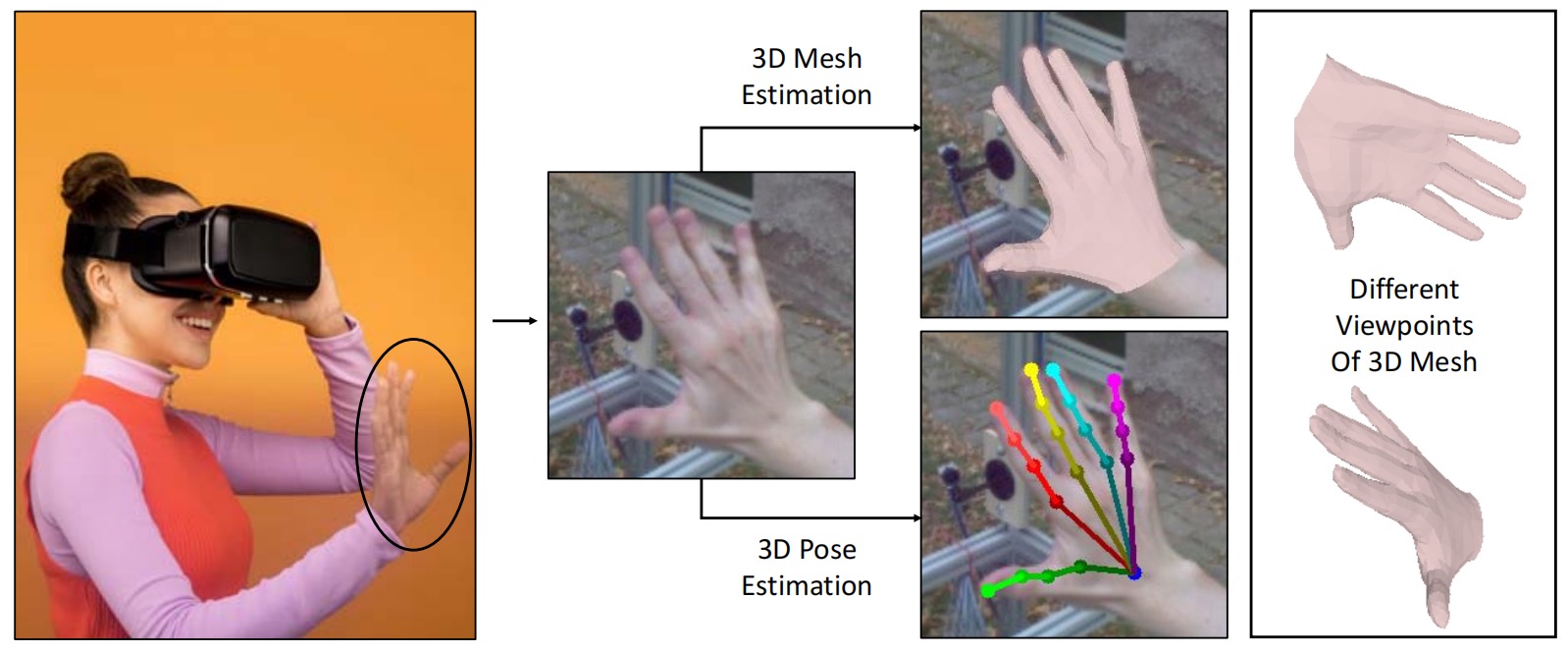
Illustration of 3D hand reconstruction from a monocular RGB image input. From the camera input (left), we reconstruct 3D hand mesh (upper right) and 3D hand pose (lower right). Because of our good balance of accuracy and efficiency, our method has more potential for real-world applications in VR/AR scenarios.
Abstract
3D hand reconstruction is a popular research topic in recent years, which has great potential for VR/AR applications. However, due to the limited computational resource of VR/AR equipment, the reconstruction algorithm must balance accuracy and efficiency to make the users have a good experience. Nevertheless, current methods are not doing well in balancing accuracy and efficiency. Therefore, this paper proposes a novel framework that can achieve a fast and accurate 3D hand reconstruction. Our framework relies on three essential modules, including spatial-aware initial graph building (SAIGB), graph convolutional network (GCN) based belief maps regression (GBBMR), and pose-guided refinement (PGR). At first, given image feature maps extracted by convolutional neural networks, SAIGB builds a spatial-aware and compact initial feature graph. Each node in this graph represents a vertex of the mesh and has vertex-specific spatial information that is helpful for accurate and efficient regression. After that, GBBMR first utilizes adaptive-GCN to introduce interactions between vertices to capture short-range and long-range dependencies between vertices efficiently and flexibly. Then, it maps vertices’ features to belief maps that can model the uncertainty of predictions for more accurate predictions. Finally, we apply PGR to compress the redundant vertices’ belief maps to compact joints’ belief maps with the pose guidance and use these joints’ belief maps to refine previous predictions better to obtain more accurate and robust reconstruction results. Our method achieves state-of-the-art performance on four public benchmarks, FreiHAND, HO-3D, RHD, and STB. Moreover, our method can run at a speed of two to three times that of previous state-of-the-art methods.
Overview
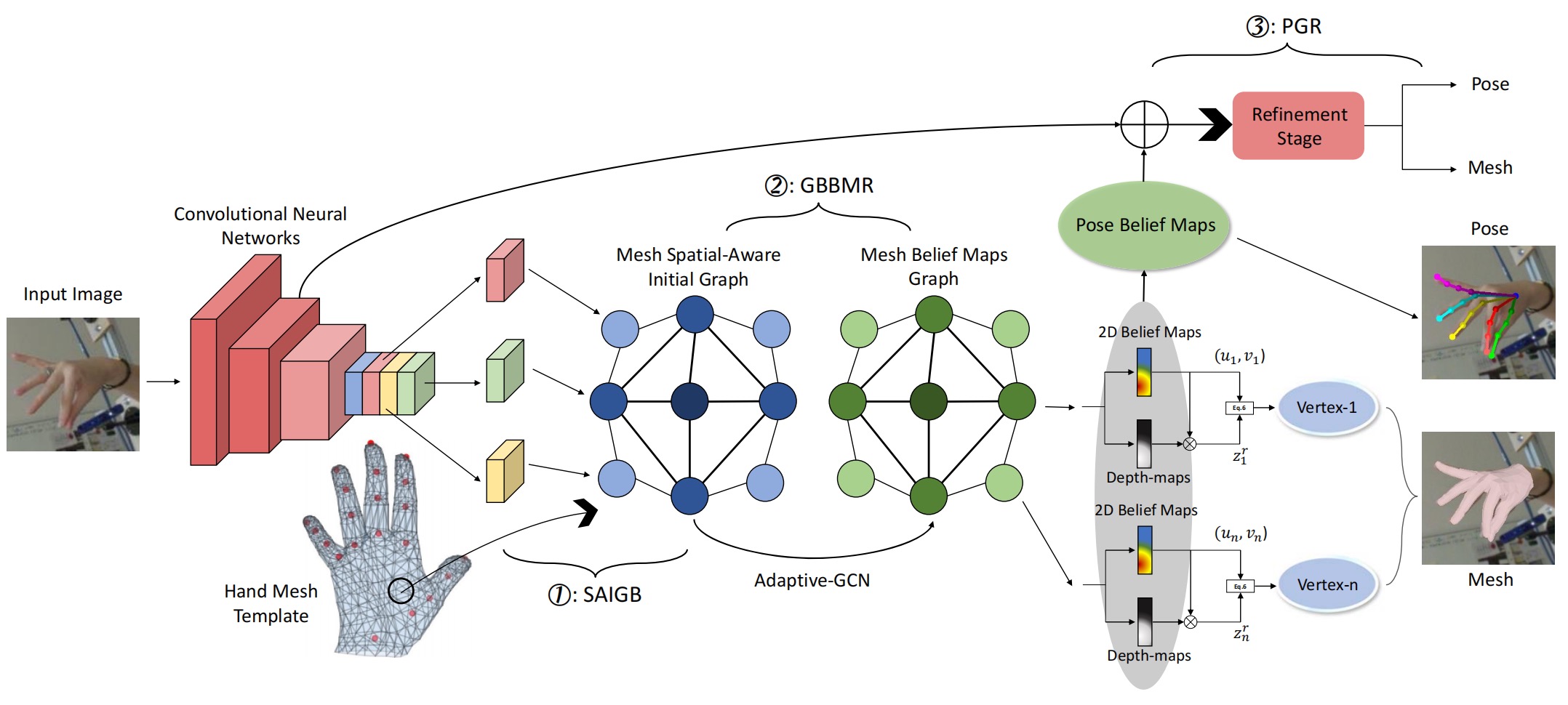
1️⃣ We first utilize convolutional neural networks to extract feature maps from the input image.
2️⃣ Then, we use SAIGB module to build a mesh initial feature graph with every vertex contains several feature maps.
3️⃣ After that, we use GBBMR module to map the initial vertex feature to vertex belief maps with Adaptive-GCN. Here, we can obtain coarse coordinates with those coarse belief maps.
4️⃣ Subsequently, we employ PGR to refine those coarse belief maps to obtain fine ones. More specifically, PGR first obtains pose joints’ belief maps from mesh vertices’ belief maps and then concatenates pose belief maps and the last stage features for refinement.
5️⃣ Finally, we use these refined coordinates as our output.
Qualitative Results

1️⃣ On FreiHAND, we can see that our method can solve unusual viewpoints and complex poses.
2️⃣ On HO-3D, our method can predict reasonable results under the occlusions caused by hand-object interaction.
3️⃣ Results on RHD and STB datasets show that our method can generalize well for other datasets.
4️⃣ Results in real-world prove our method has the cross-domain generalization ability.
These results prove our method has the cross-domain generalization ability and great potential for VR/AR applications.
Comparisons with SOTA
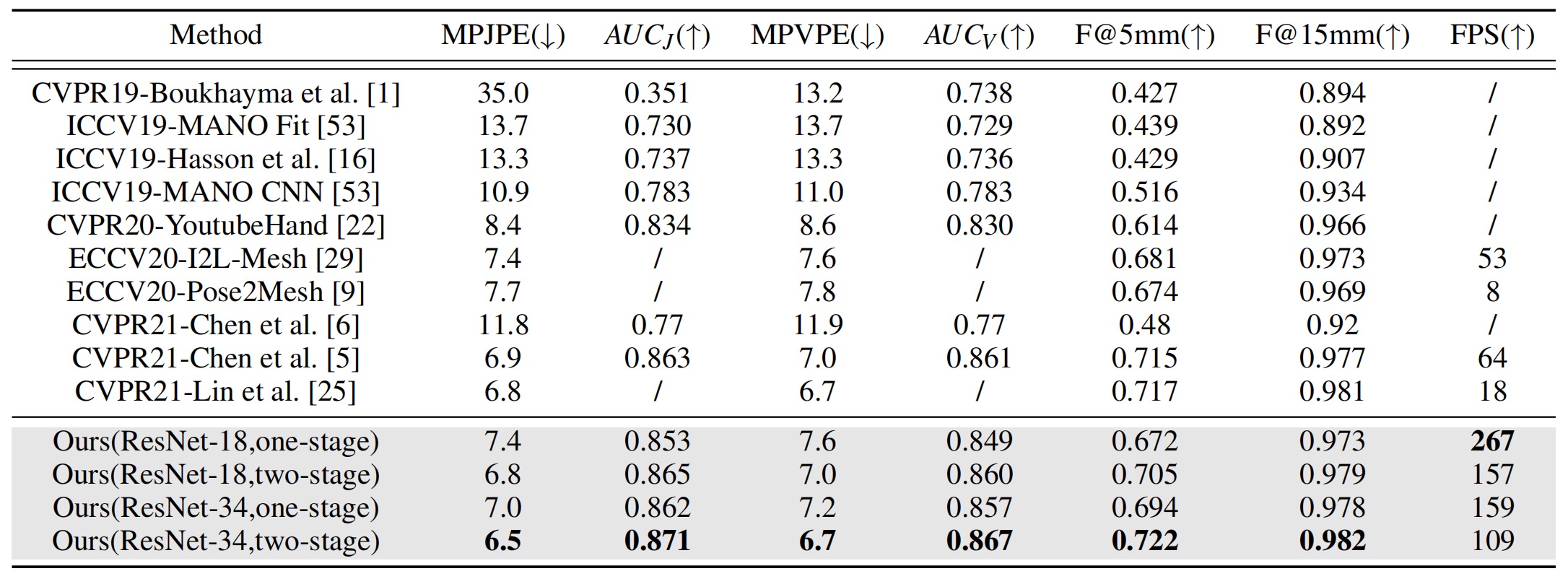
FreiHAND: Our method outperforms other methods in terms of all the aforementioned metrics. Moreover, we compare the inference speed of our method with other methods using the same computer. Our method has a much faster inference speed due to the simplicity of our method.

FreiHAND: We find that the model training on this dataset tends to overfit. Therefore, we utilize weights pre-trained on FreiHAND for regularization. In this way, our method outperforms four recent works in a large margin. When directly training on this dataset, our method can still achieve state-of-the-art performance.
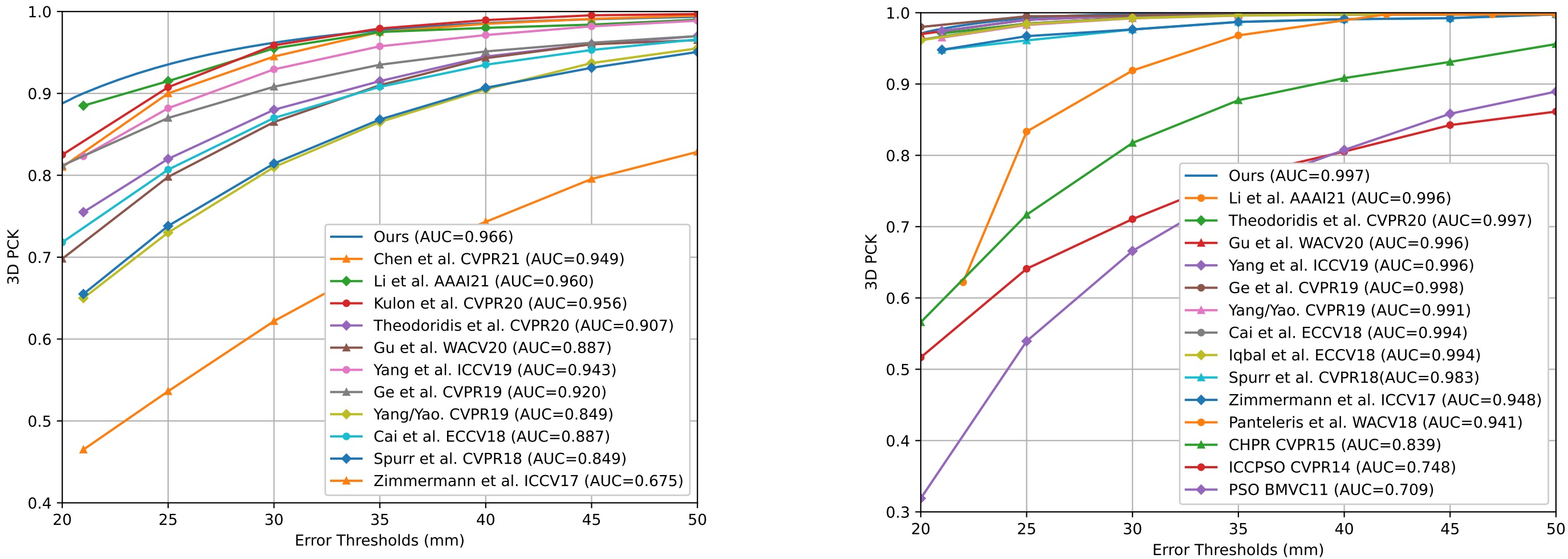
Comparisons of 3D PCK on RHD dataset.
Comparisons of 3D PCK on STB dataset.
RHD and STB: Our method is a general framework that can adapt to pose estimation task. our method outperforms all other methods on RHD dataset and achieve comparable performance on STB dataset with other methods. Because STB is relatively easier than other datasets, recent methods all perform similarly on this dataset.
Conclusion
In this paper, we propose a simple and effective framework for 3D hand reconstruction from a monocular RGB image. Our method introduces three impressive ideas of detection-based methods to regression-based methods framework, including preserving spatial information, modeling uncertainty, and introducing refinement strategy. We achieve these three ideas with our proposed SAIGB, GBBMR, and PGR, respectively. Extensive experiments on four public benchmarks demonstrate that our method achieves state-of-the-art performance as well as the highest inference speed. Because of this good balance of accuracy and efficiency, our method has more potential for real-world applications in VR/AR scenarios.
Bibtex
@inproceedings{zheng2021sar,
title={Sar: Spatial-aware regression for 3d hand pose and mesh reconstruction from a monocular rgb image},
author={Zheng, Xiaozheng and Ren, Pengfei and Sun, Haifeng and Wang, Jingyu and Qi, Qi and Liao, Jianxin},
booktitle={2021 IEEE International Symposium on Mixed and Augmented Reality (ISMAR)},
pages={99--108},
year={2021},
organization={IEEE}
}