
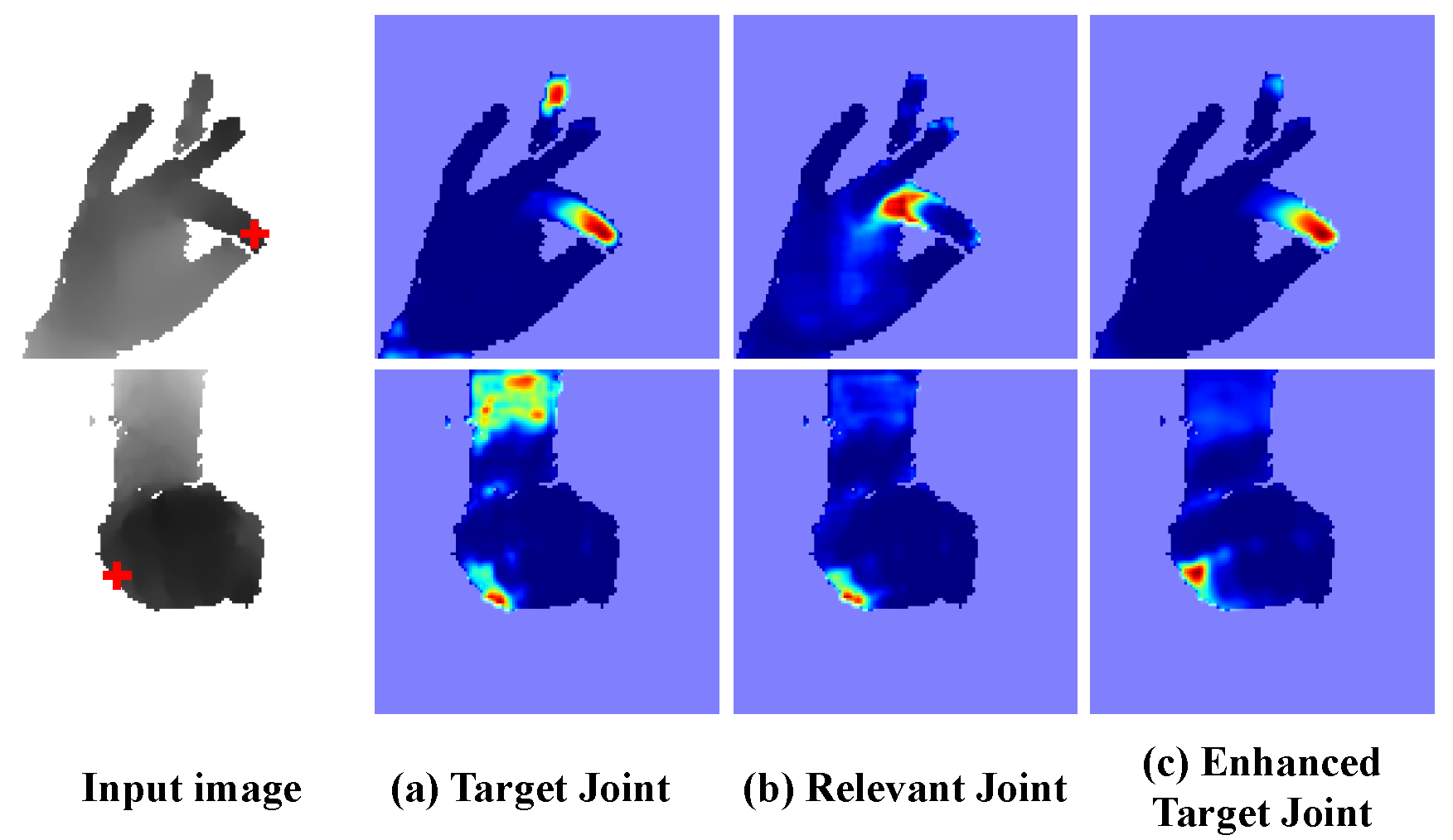
Due to the self-similarity of the fingers and severe self-occlusion, it is difficult to predict the correct joint position from local evidence (as shown in Fig. a). By incorporating context information (as shown in Fig. b, where adjacent joints can be accurately predicted), forming enhanced feature maps through pose-guided hierarchical graph (PHG), ambiguity is effectively reduced (as shown in Fig. c).
Abstract
Estimating 3-D hand pose estimation from a single depth image is important for human–computer interaction. Although depth-based 3-D hand pose estimation has made great progress in recent years, it is still difficult to deal with some complex scenes, especially the issues of serious self-occlusion and high self-similarity of fingers. Inspired by the fact that multipart context is critical to alleviate ambiguity, and constraint relations contained in the hand structure are important for robust estimation, we attempt to explicitly model the correlations between different hand parts. In this article, we propose a pose-guided hierarchical graph convolution (PHG) module, which is embedded into the pixelwise regression framework to enhance the convolutional feature maps by exploring the complex dependencies between different hand parts. Specifically, the PHG module first extracts hierarchical fine-grained node features under the guidance of hand pose and then uses graph convolution to perform hierarchical message passing between nodes according to the hand structure. Finally, the enhanced node features are used to generate dynamic convolution kernels to generate hierarchical structure-aware feature maps. Our method achieves state-of-the-art performance or comparable performance with the state-of-the-art methods on five 3-D hand pose datasets: HANDS 2019, HANDS 2017, NYU, ICVL, and MSRA.
Overview
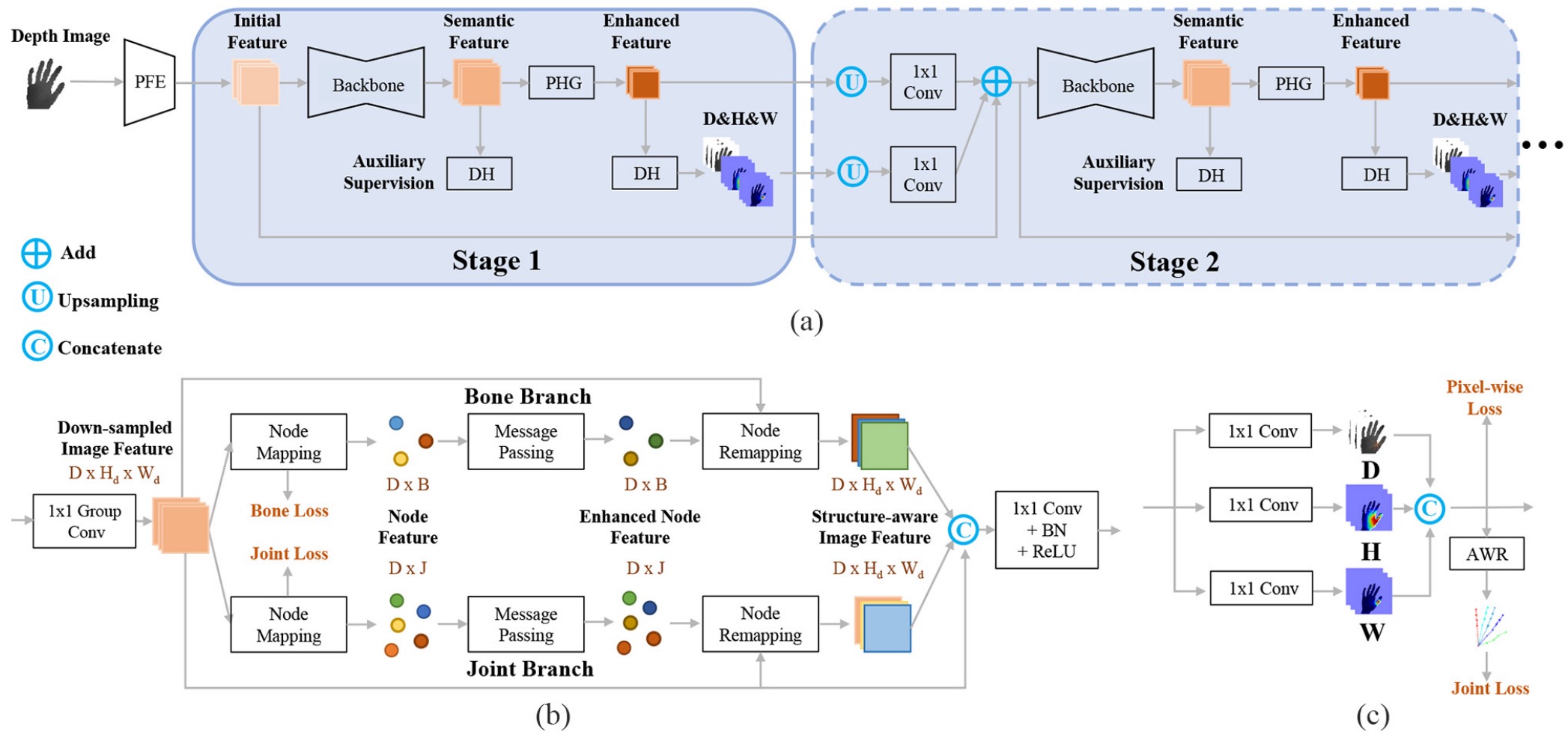
1️⃣ A PFE module extracts the initial feature maps from the depth image.
2️⃣ The backbone adopts an encoding-decoding structure to generate the feature maps with high-level semantics.
3️⃣ The PHG module generates enhanced feature maps by utilizing dependency among different hand parts.
4️⃣ The DH module is used to perform the pixelwise estimation. In particular, adding a DH after the backbone is able to provide an auxiliary loss to reduce the difficulty of network training.
Our network can also contain multiple stages. If network stacking is performed, as shown in stage 2, two 1×1 convolutions, respectively, remap the upsampled pixelwise estimations and the upsampled enhanced feature maps to the intermediate features, which are added with initial feature maps and fed to the subsequent subnetwork.
Qualitative result

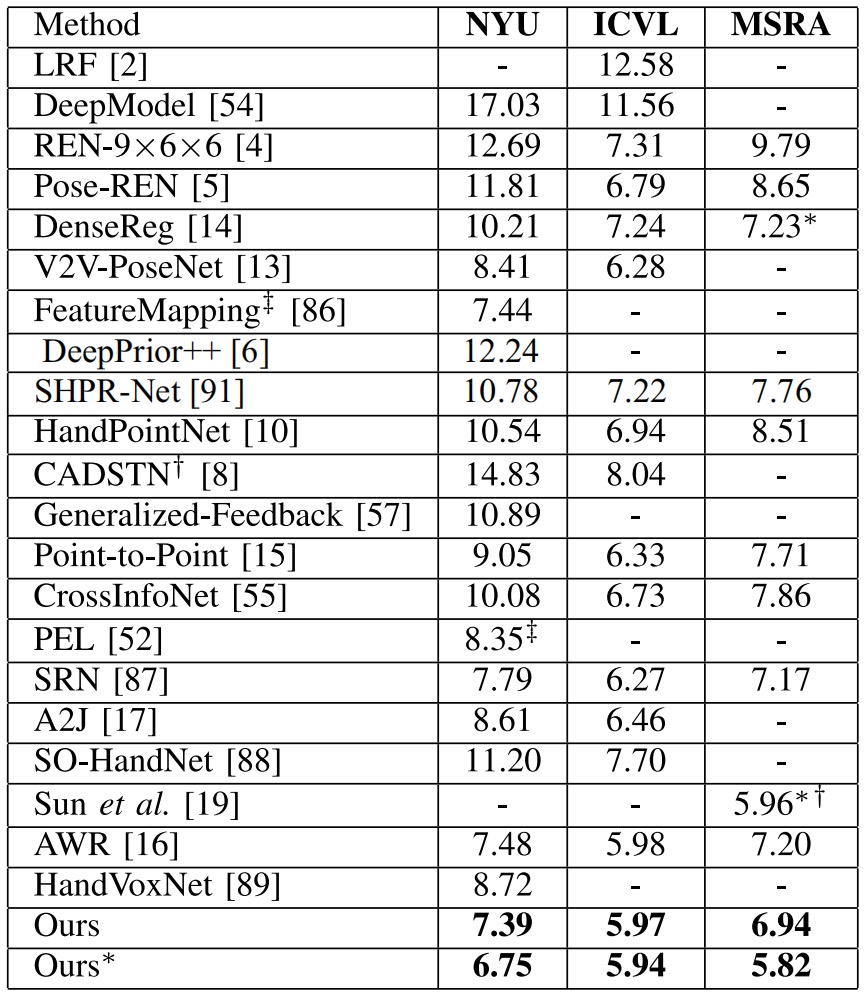
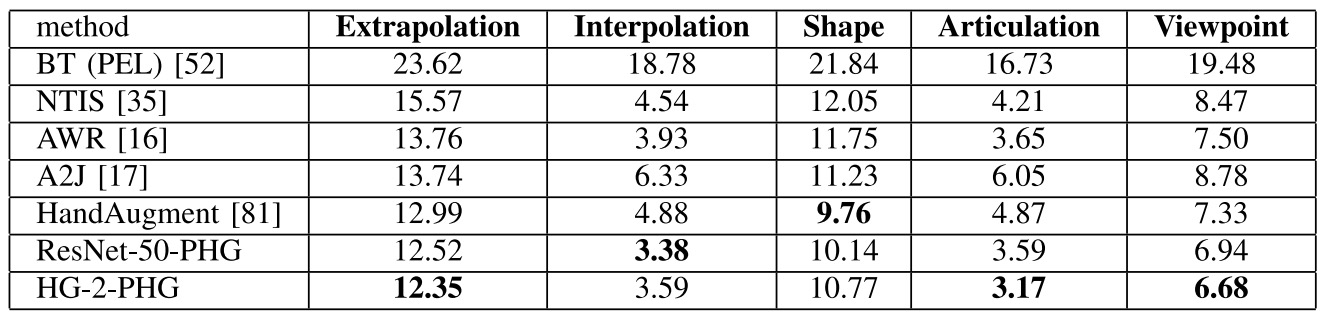
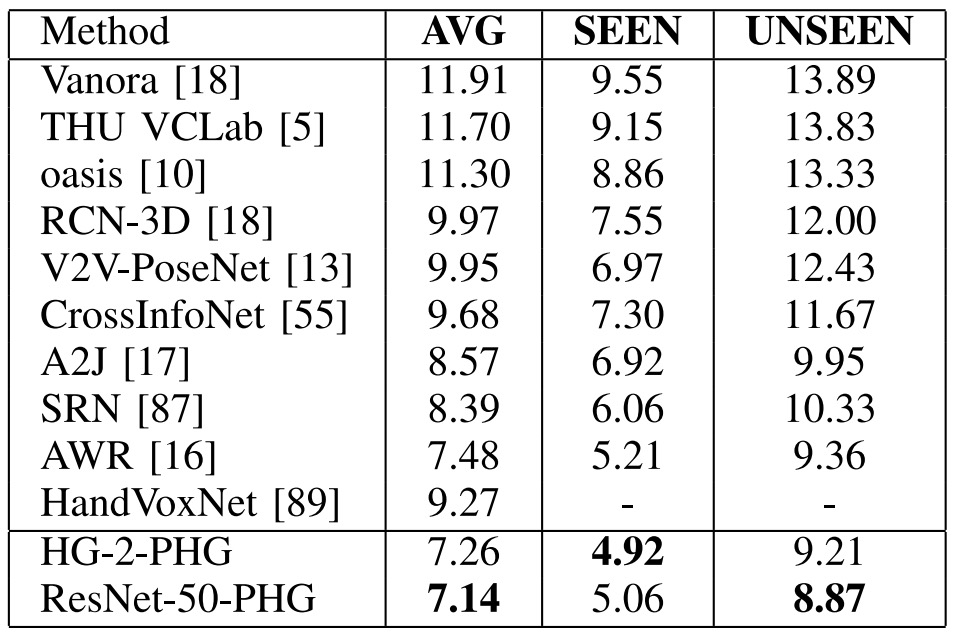
Comparison with SOTA
Conclusion
We introduced a PHG Network for robust and accurate 3-D hand pose estimation. Our method was embedded in the pixelwise regression framework, which can maintain the spatial structure of feature maps while capturing the complex short and long-range dependency of different hand regions. We proposed the following:
1️⃣ A node mapping module to extract fine-grained node features, guided by the hand pose information.
2️⃣ The residual graph convolution module, which performs iterative and hierarchical message passing. This module is able to capture the complex dependency relations between joints and bones.
3️⃣ The enhanced node features are dynamically encoded into a set of convolution kernels throuh node remapping module to generate hierarchical structure-aware feature maps, which can be used for more accurate and robust hand pose estimation.
Our method is particularly effective in handling cases with severe self-similarity and self-occlusion. Extensive experiments on five public hand datasets demonstrated the effectiveness of our approach.
Bibtex
@article{ren2021pose,
title={Pose-guided hierarchical graph reasoning for 3-d hand pose estimation from a single depth image},
author={Ren, Pengfei and Sun, Haifeng and Hao, Jiachang and Qi, Qi and Wang, Jingyu and Liao, Jianxin},
journal={IEEE Transactions on Cybernetics},
volume={53},
number={1},
pages={315--328},
year={2021},
publisher={IEEE}
}