
Normal hand

Small hand
Demos above are realtime results from Kinect V2 using models trained on Hands17 dataset (Intel Realsense SR300).
Abstract
Recently, most of state-of-the-art methods are based on 3D input data, because 3D data capture more spatial information than the depth image. However, these methods either require a complex network structure or time-consuming data preprocessing and post-processing. We present a simple and accurate method for 3D hand pose estimation from a 2D depth image. This is achieved by a differentiable re-parameterization module, which constructs 3D heatmaps and unit vector fields from joint coordinates directly. Taking the spatial-aware representations as intermediate features, we can easily stack multiple regression modules to capture spatial structures of depth data for accurate and robust estimation. Furthermore, we explore multiple good practices to improve the performance of the 2D CNN for 3D hand pose estimation. Experiments on four challenging hand pose datasets show that our proposed method outperforms all state-of-the-art methods with faster inference speed.
Overview
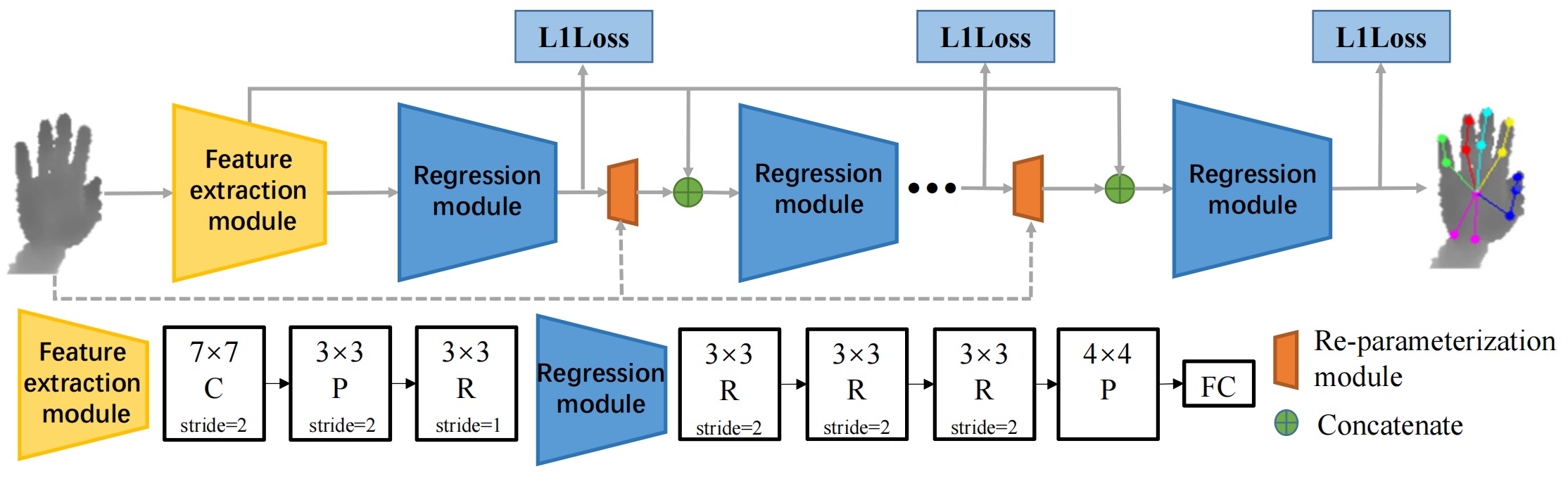
SRN consists of a feature extraction module and multiple regression modules which are connected by the re-parameterization module.
1️⃣ Firstly, the input image is passed through the feature extraction module, which helps reduce computational cost by generating low-resolution feature maps (preliminary features).
2️⃣ Then, the regression modules estimate the joint coordinates in turn, while intermediate supervision (L1 Loss) is applied at the end of each module.
3️⃣ Specifically, in addition to the first regression module, whose input contains only the preliminary features, the other regression modules also take 3D heat maps and unit vector fields (output of re-parameterization module) along with the preliminary features as input.
Comparison with SOTA
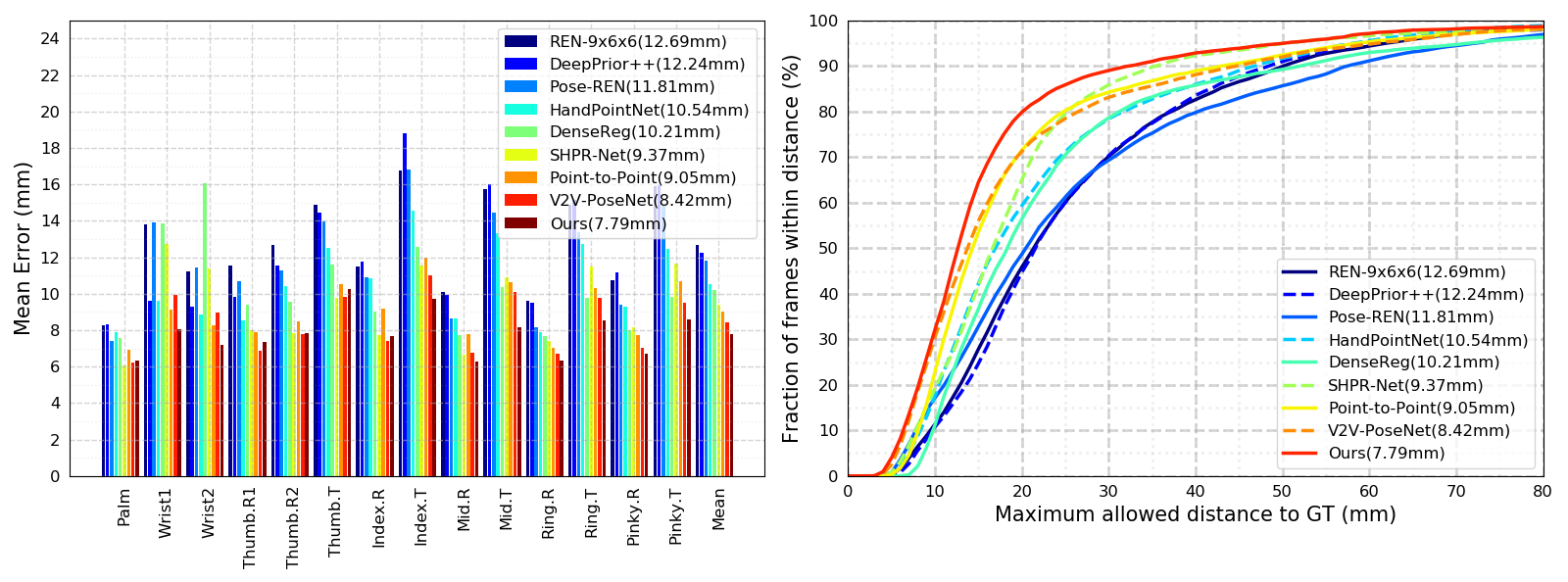
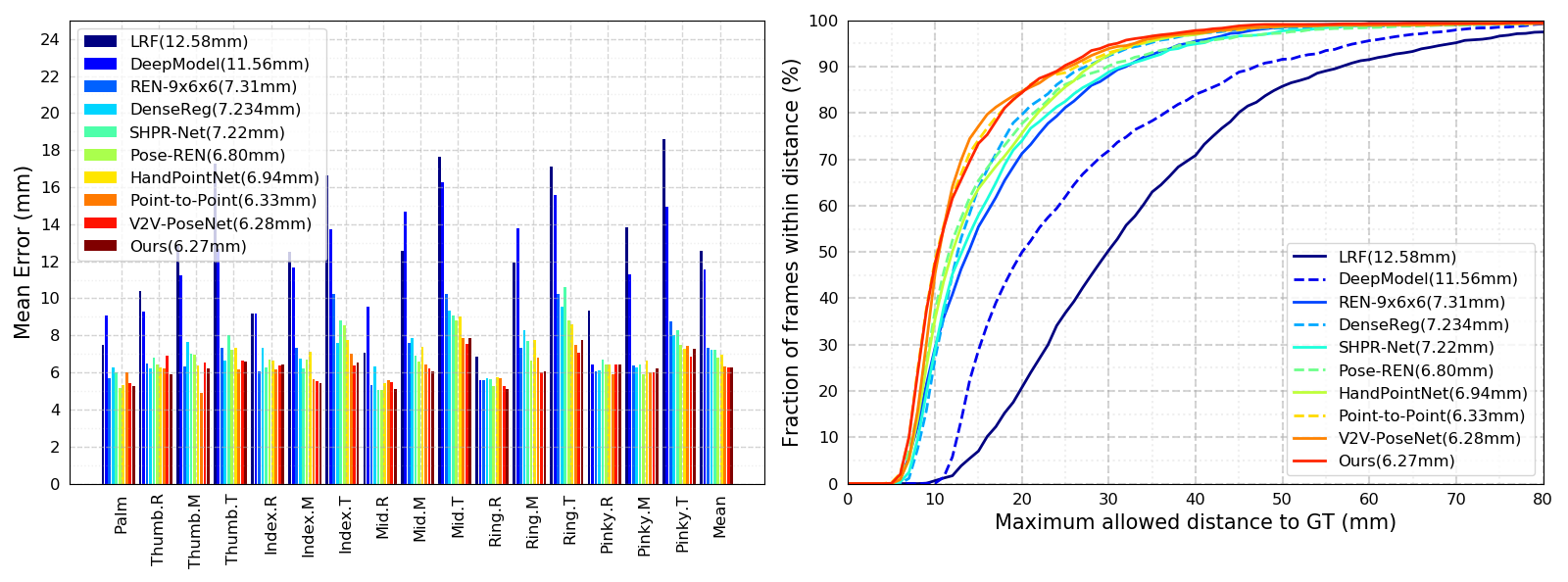
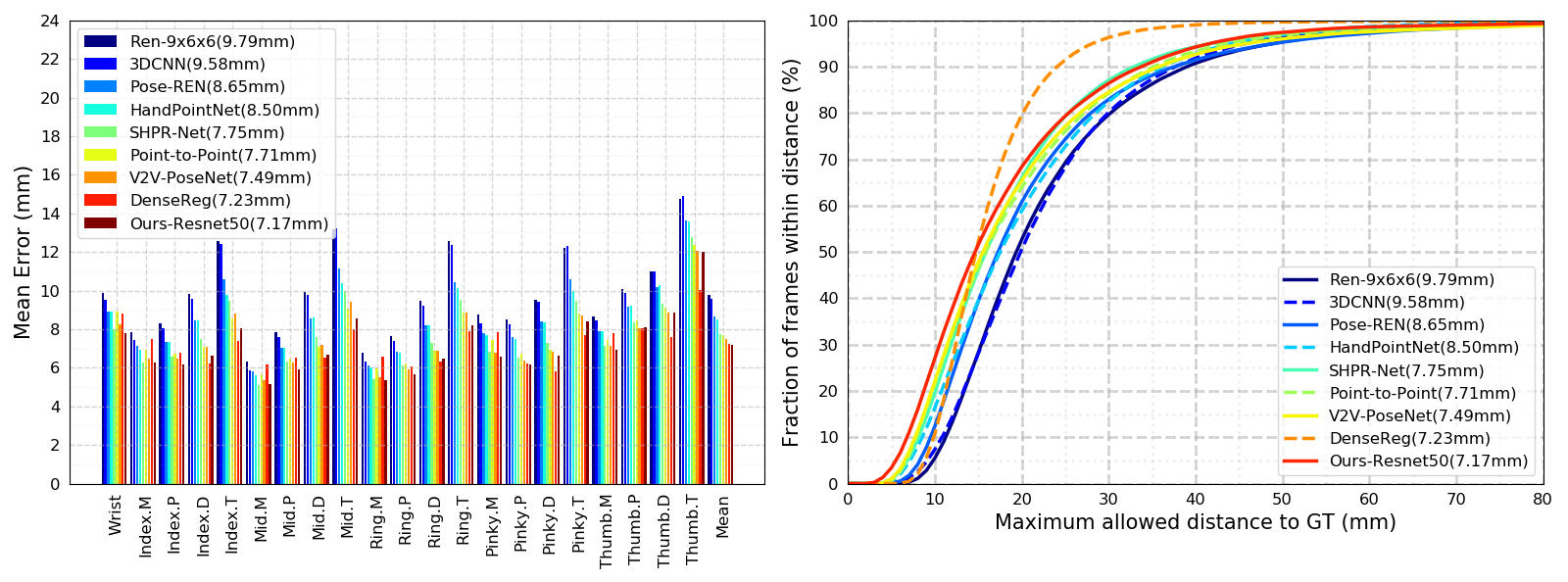
Comparison of the proposed method (SRN) with state-of-the-art methods. The proportions of good frames and the overall mean error distances (in parentheses) are presented in these figures.

Conclusion
In this paper, we present a simple but powerful network called Stacked Regression Network (SRN) for 3D hand pose estimation from single depth map inputs.
1️⃣ By exploring some good practices, we make full use of the potential of 2D CNN.
2️⃣ We stack multiple regression networks together using pose re-parameterization, which allows the network to consider the 3D properties of the depth map and reevaluate the initial estimations.
3️⃣ The repeated regression process helps our network capture global constraints and correlations between different joints, making it more robust to self-occlusion and image missing.
Experimental results on four challenging hand pose datasets demonstrate that our method achieves superior accuracy and robust performance with less complexity and faster inference time.
Bibtex
@inproceedings{ren2019srn,
title={SRN: Stacked regression network for real-time 3D hand pose estimation.},
author={Ren, Pengfei and Sun, Haifeng and Qi, Qi and Wang, Jingyu and Huang, Weiting},
booktitle={BMVC},
volume={112},
year={2019}
}